
使用Python 3.9和Pytorch 1.13分析了所有数据。
Tasks and datasets
任务和数据集
No statistical methods were used to predetermine sample sizes in this study. All datasets were drawn from previously published studies, and we included all available subjects (with enough trials for modelling) in each task. Allocation to experimental groups was not randomized by us; instead, randomization was previously performed by the original authors. Our study does not include any direct behavioural experimentation. Therefore, blinding was not required.
在这项研究中,没有使用统计方法来预先确定样本量。所有数据集均来自先前发表的研究,我们在每个任务中包括了所有可用的主题(并进行了足够的试验)。分配给实验组不是我们随机分配的。取而代之的是,随机化以前是由原始作者执行的。我们的研究不包括任何直接的行为实验。因此,不需要盲目。
Reversal learning task
逆转学习任务
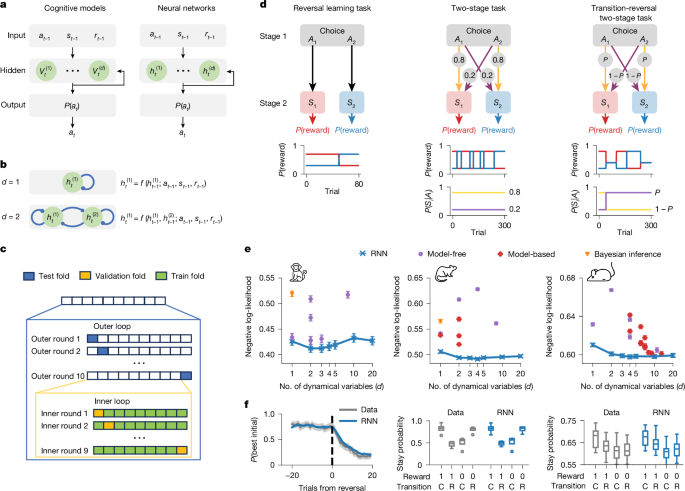
The reversal learning task is a paradigm designed to assess subjects’ ability to adapt their behaviour in response to changing reward contingencies. In each trial, subjects are presented with two actions, A 1 and A 2 , yielding a unit reward with probability \({p}_{1}^{{\rm{reward}}}\) and \({p}_{2}^{{\rm{reward}}}\), respectively. These reward probabilities remain constant for several trials before switching unpredictably and abruptly, without explicit cues. When this occurs, the action associated with the higher reward probability becomes linked to the lower reward probability, and vice versa. The task necessitates continuous exploration of which action currently has a higher reward probability in order to maximize total rewards. For consistency with the other animal tasks, we assume that actions (A 1 and A 2 ) are made at the choice state, and A i deterministically leads to state S i , where the reward is delivered.
逆转学习任务是一种范式,旨在评估受试者适应其行为的能力,以应对不断变化的奖励意外事件。在每个试验中,对受试者都会呈现两个动作A 1和A 2,并获得单位奖励,并具有概率\({p} _ {1}^{{\ rm {Reward}}}}}} \)和\({p} _ {2}}^{2}^{{\ rm {{\ rm {{\ rm {{这些奖励概率对于多项试验仍然不变,然后在没有明确提示的情况下不可预测和突然切换。发生这种情况时,与较高奖励概率相关的动作与较低的奖励概率相关,反之亦然。该任务需要对哪种操作当前具有更高奖励概率的持续探索才能最大程度地提高总奖励。为了与其他动物任务保持一致,我们假设在选择状态下采取行动(A 1和A 2),并且我确定地导致了奖励提供的状态。
In the Bartolo dataset10,48,49, 2 male monkeys (Rhesus macaque, Macaca mulatta; age 4.5 years) completed a total of 15,500 trials of the reversal learning task with 2 state-reward types: (1) \({p}_{1}^{{\rm{reward}}}=0.7\) and \({p}_{2}^{{\rm{reward}}}=0.3\); (2) \({p}_{1}^{{\rm{reward}}}=0.3\) and \({p}_{2}^{{\rm{reward}}}=0.7\). Blocks were 80 trials long, and the switch happened at a ‘reversal trial’ between trials 30 and 50. We predicted the behaviour from trials 10 to 70, similar to the original preprocessing procedure10 because the monkeys were inferring the current block type (‘what’ block, choosing from two objects; ‘where’ block, choosing from two locations) in the first few trials.
在Bartolo DataTet10,48,49中,2个男性猴子(Rhesus Macaque,Macaca Mulatta; 4.5岁)完成了15,500次逆转学习任务的试验,具有2种状态奖励类型:(1)\({p} _ {2}^{{\ rm {ready}}}} = 0.3 \);(2)\({p} _ {1}^{{\ rm {ready}}}} = 0.3 \)和\({p} _ {2}^{2}^{{\ rm {Reward}}}}}}}}}} = 0.7 \)。块长80次试验,然后进行转换在试验30到50之间的“逆转试验”中。我们预测了试验10到70的行为,类似于原始的预处理程序10,因为猴子在第一个试验中推断了当前的块类型(从两个位置选择“从两个位置”中选择“从两个位置进行选择”)。
In the Akam dataset11,50, 10 male mice (C57BL6; aged between 2–3 months) completed a total of 67,009 trials of the reversal learning task with 3 state-reward types: (1) \({p}_{1}^{{\rm{reward}}}=0.75\) and \({p}_{2}^{{\rm{reward}}}=0.25\); (2) \({p}_{1}^{{\rm{reward}}}=0.25\) and \({p}_{2}^{{\rm{reward}}}=0.75\); (3) \({p}_{1}^{\text{reward}}=0.5\) and \({p}_{2}^{{\rm{reward}}}=0.5\) (neutral trials). Block transitions from non-neutral blocks were triggered 10 trials after an exponential moving average (tau = 8 trials) crossed a 75% correct threshold. Block transitions from neutral blocks occurred with a probability of 10% on each trial after the 15th of the block to give an average neutral block length of 25 trials.
在AKAM数据集11,50中,10个雄性小鼠(C57BL6;年龄在2-3个月之间),完成了67,009个反向学习任务的试验,具有3种状态奖励类型:(1)\({p} _ {1} _ {1}^{{\ rm {{\ rm {\ rm {{\ rm {{\ rm {{\ rm {{\({p} _ {2}^{{\ rm {newrk}}}} = 0.25 \);(2)\({p} _ {1}^{{{\ rm {ready}}} = 0.25 \)和\({p} _ {2} _ {2}^{{\ rm {Reward}}}}}}}}}}}}} = 0.75 \ \ \);(3)\({p} _ {1}^{\ text {newd}} = 0.5 \)和\({p} _ {2}^{{\ rm {nrewh}}} = 0.5 \ 0.5 \)(中性试验)。在指数移动平均值(TAU = 8个试验)越过75%的正确阈值后,触发了从非中性块的块转换10次试验。从中性块发生的块转变发生在块15块后的每个试验中,每次试验的概率为10%,从而给出了25个试验的平均中性块长度。
Two-stage task
两个阶段任务
The two-stage task is a paradigm commonly used to distinguish between the influences of model-free and model-based RL on animal behaviour51, and later reduced in ref. 34. In each trial, subjects are presented with two actions, A 1 and A 2 , while at the choice state. Action A 1 leads with a high probability to state S 1 and a low probability to state S 2 , while action A 2 leads with a high probability to state S 2 and a low probability to state S 1 . From second-stage states S 1 and S 2 , the animal can execute an action for a chance of receiving a unit reward. Second-stage states are distinguishable by visual cues and have different probabilities of yielding a unit reward: \({p}_{1}^{{\rm{reward}}}\) for S 1 and \({p}_{2}^{{\rm{reward}}}\) for S 2 . These reward probabilities remain constant for several trials before switching unpredictably and abruptly. When this occurs, the second-stage state associated with the higher reward probability becomes linked to the lower reward probability, and vice versa.
两个阶段的任务是一种通常用于区分无模型和基于模型的RL对动物行为的影响的范例,然后在参考文献中减少。34。在每个试验中,在选择状态下,在每个试验中都会有两个动作,A 1和A 2。ACTION A 1导致陈述s 1的可能性很高,陈述s 2的概率很低,而动作A 2导致陈述s 2的可能性很高,并且陈述s 1的可能性较低。从第二阶段的s 1和s 2中,动物可以执行行动,有机会获得单位奖励。第二阶段状态可通过视觉提示区分,并且具有单位奖励的不同概率:\({p} _ {1}^{{\ rm {ready {Reward}}}} \)对于S 1 and {p} _ {p} _ {2} _这些奖励概率在多次试验中仍然保持不变,然后不可预测,突然切换。发生这种情况时,与较高奖励概率相关的第二阶段状态与较低的奖励概率相关,反之亦然。
In the Miller dataset12,52, 4 adult male Long-Evans rats (Taconic Biosciences; Hilltop Lab Animals) completed a total of 33,957 trials of the two-stage task with 2 state-reward types: (1) \({p}_{1}^{{\rm{reward}}}=0.8\) and \({p}_{2}^{{\rm{reward}}}=0.2\); (2) \({p}_{1}^{{\rm{reward}}}=0.2\) and \({p}_{2}^{{\rm{reward}}}=0.8\). Block switches occurred with a 2% probability on each trial after a minimum block length of 10 trials.
在Miller DataSet12,52中,4名成年男性长埃文斯大鼠(Taconic Biosciences; Hilltop Lab Alimal)在两阶段任务中总共完成了33,957个试验,具有2种状态奖励类型:(1)\({p} _ {1} _ {1} _ {1}^{\ rm {{\ rm {{\ rm {{\ rm {{\ rm {0.8)\({p} _ {2}^{{\ rm {ready}}}} = 0.2 \);(2)\({p} _ {1}^{{\ rm {ready}}}}} = 0.2 \)和\({p} _ {2}^{\ rm {Reward}}}}}}}}}}} = 0.8 \)。在最小块长度为10个试验后,每次试验的概率发生2%。
In the Akam dataset11,50, 10 male mice (C57BL6; aged between 2–3 months) completed a total of 133,974 trials of the two-stage task with 3 state-reward types: (1) \({p}_{1}^{{\rm{reward}}}=0.8\) and \({p}_{2}^{{\rm{reward}}}=0.2\); (2) \({p}_{1}^{{\rm{reward}}}=0.2\) and \({p}_{2}^{{\rm{reward}}}=0.8\); (3) \({p}_{1}^{{\rm{reward}}}=0.4\) and \({p}_{2}^{{\rm{reward}}}=0.4\) (neutral trials). Block transitions occur 20 trials after an exponential moving average (tau = 8 trials) of the subject’s choices crossed a 75% correct threshold. In neutral blocks, block transitions occurred with 10% probability on each trial after the 40th trial. Transitions from non-neutral blocks occurred with equal probability either to another non-neutral block or to the neutral block. Transitions from neutral blocks occurred with equal probability to one of the non-neutral blocks.
在AKAM数据集11,50中,10个雄性小鼠(C57BL6;年龄在2-3个月之间),总共完成了133,974个两阶段任务的试验,具有3种状态奖励类型:(1)\({p} _ {1} _ {1}^{1}^{{\ rm {{\ rm {{\ rm {{\ rm {{\ rm {{\({p} _ {2}^{{\ rm {ready}}}} = 0.2 \);(2)\({p} _ {1}^{{{\ rm {ready}}}} = 0.2 \)和\({p} _ {2}^{2}^{{\ rm {Reward}}}}}}}}}}}}} = 0.8 \);(3)\({p} _ {1}^{{\ rm {ready}}}} = 0.4 \)和\({p} _ {2}^{\ rm {Reward}}}}}}}} = 0.4 \)(中立试验)。在受试者选择的指数移动平均值(TAU = 8个试验)之后,块过渡发生了20次试验,越过了75%的正确阈值。在中性块中,第40次试验后,每次试验的概率为10%。从非中性块的过渡发生在另一个非中性块或中性块的概率上。从中性块的过渡发生,概率相等,向一个非中性块之一。
Transition-reversal two-stage task
过渡 - 反转两阶段任务
The transition-reversal two-stage task is a modified version of the original two-stage task, with the introduction of occasional reversals in action-state-transition probabilities11. This modification was proposed to facilitate the dissociation of state prediction and reward prediction in neural activity and to prevent habit-like strategies that may produce model-based control-like behaviour without forward planning. In each trial, subjects are presented with two actions, A 1 and A 2 , at the choice state. One action commonly leads to state S 1 and rarely to state S 2 , while the other action commonly leads to state S 2 and rarely to state S 1 . These action-state-transition probabilities remain constant for several trials before switching unpredictably and abruptly, without explicit cues. In the second-stage states S 1 and S 2 , subjects execute an action for a chance of receiving a unit reward. The second-stage states are visually distinguishable and have different reward probabilities that also switch unpredictably and abruptly, without explicit cues, similar to the other two tasks.
过渡 - 反转两阶段任务是原始两阶段任务的修改版本,并在Action-State-Transition-Transition概率中引入了偶尔的逆转11。提出了这种修改,以促进在神经活动中的国家预测和奖励预测的解离,并防止习惯样策略,这些策略可能在没有远期计划的情况下可能会产生基于模型的控制行为。在每个试验中,在选择状态下,向受试者呈现两个动作A 1和A 2。一种行动通常导致状态1,很少导致s 2,而另一个行动通常导致状态s 2,很少导致s 1。在没有明确提示的情况下,这些动作状态 - 状态转变概率在不可预测和突然地切换之前一直保持恒定。在第二阶段的s 1和s 2中,受试者执行了一项行动,有机会获得单位奖励。第二阶段的状态在视觉上是可区分的,并且具有不同的奖励概率,这些奖励概率也可以不可预测,无明确提示,类似于其他两个任务。
In the Akam dataset11,50, 17 male mice (C57BL6; aged between 2–3 months) completed a total of 230,237 trials of the transition-reversal two-stage task with 2 action-state types: (1) Pr(S 1 ∣A 1 ) = Pr(S 2 ∣A 2 ) = 0.8 and Pr(S 2 ∣A 1 ) = Pr(S 1 ∣A 2 ) = 0.2; (2) Pr(S 1 ∣A 1 ) = Pr(S 2 ∣A 2 ) = 0.2 and Pr(S 2 ∣A 1 ) = Pr(S 1 ∣A 2 ) = 0.8. There were also 3 state-reward types: (1) \({p}_{1}^{{\rm{reward}}}=0.8\) and \({p}_{2}^{{\rm{reward}}}=0.2\); (2) \({p}_{1}^{{\rm{reward}}}=0.2\) and \({p}_{2}^{{\rm{reward}}}=0.8\); (3) \({p}_{1}^{{\rm{reward}}}=0.4\) and \({p}_{2}^{{\rm{reward}}}=0.4\) (neutral trials). Block transitions occur 20 trials after an exponential moving average (tau = 8 trials) of the subject’s choices crossed a 75% correct threshold. In neutral blocks, block transitions occurred with 10% probability on each trial after the 40th trial. Transitions from non-neutral blocks occurred with equal probability (25%) either to another non-neutral block via reversal in the reward or transition probabilities, or to one of the two neutral blocks. Transitions from neutral blocks occurred via a change in the reward probabilities only to one of the non-neutral blocks with the same transition probabilities.
在AKAM数据集11,50中,17只雄性小鼠(C57BL6;年龄在2-3个月之间)完成了230,237个转变 - 反转两阶段任务的试验,具有2种动作状态类型:(1)PR(S 1°1)= PR(S 2)= PR(S 2°2)= 0.8和Pr(S 2°2)= 0.8和Pr(s 2)= 0.2 = 0.2 = 0.2 = pr(s 1)= 0.2 pr(s 1)= a 2 r(s 1)= a 1)(2)pr(s 1°A 1)= pr(s 2°2)= 0.2和pr(s 2°1)= pr(s 1°2)= 0.8。也有3种状态奖励类型:(1)\({p} _ {1}^{{{\ rm {newrk}}}} = 0.8 \)和\({p} _ {2} _ {2}^{{\ rm {newd}}} = 0.2 = 0.2 = 0.2 \ \);(2)\({p} _ {1}^{{{\ rm {ready}}}} = 0.2 \)和\({p} _ {2}^{2}^{{\ rm {Reward}}}}}}}}}}}}} = 0.8 \);(3)\({p} _ {1}^{{\ rm {ready}}}} = 0.4 \)和\({p} _ {2}^{\ rm {Reward}}}}}}}} = 0.4 \)(中立试验)。在受试者选择的指数移动平均值(TAU = 8个试验)之后,块过渡发生了20次试验,越过了75%的正确阈值。在中性块中,第40次试验后,每次试验的概率为10%。从非中性块的过渡是通过奖励或过渡概率的反转或两个中性块之一的反转,以相等的概率(25%)到另一个非中性块发生过渡。从中性块的过渡是通过更改奖励概率的变化而发生的,仅向具有相同过渡概率的非中性块之一。
Three-armed reversal learning task
三臂逆转学习任务
In the Suthaharan dataset53, 1,010 participants (605 participants from the pandemic group and 405 participants from the replication group) completed a three-armed probabilistic reversal learning task. This task was framed as either a non-social (card deck) or social (partner) domain, each lasting 160 trials divided evenly into 4 blocks. Participants were presented with 3 actions (A 1 , A 2 and A 3 ; 3 decks of cards in the non-social domain frame or 3 avatar partners in the social domain frame), each containing different amounts of winning (+100) and losing (−50) points. The objective was to find the best option and earn as many points as possible, knowing that the best option could change.
在Suthaharan DataSet53中,有1,010名参与者(来自大流行小组的605名参与者和来自复制小组的405名参与者)完成了一项三臂概率的逆转学习任务。该任务被构成非社交(卡片甲板)或社交(合作伙伴)领域,每个持续的160个试验均匀分为4个块。向参与者提供了3个动作(A 1,A 2和A 3; 3张在非社交领域框架中的纸牌或社会领域框架中的3个Avatar伙伴),每个牌中都包含不同数量的获胜(+100)和丢失(-50)点。目的是找到最佳选择并获得尽可能多的积分,因为知道最佳选择可能会改变。
The task contingencies started with 90%, 50% and 10% reward probabilities, with the best deck/partner switching after 9 out of 10 consecutive rewards. Unknown to the participants, the underlying contingencies transitioned to 80%, 40%, and 20% reward probabilities at the end of the second block, making it more challenging to distinguish between probabilistic noise and genuine changes in the best option.
任务意外事件从90%,50%和10%的奖励概率开始,在连续10个奖励中,最佳甲板/合作伙伴切换。参与者未知,在第二块区域结束时,基础偶然性转变为80%,40%和20%的奖励概率,从而使概率噪音和最佳选择的真实变化更具挑战性。
Four-armed drifting bandit task
四臂漂流匪徒任务
The Bahrami dataset54 includes 975 participants who completed the 4-arm bandit task55. Participants were asked to choose between 4 options on 150 trials. On each trial, they chose an option and were given a reward. The rewards for each option drifted over time in a manner known as a restless bandit, forcing the participants to constantly explore the different options to obtain the maximum reward. The rewards followed one of three predefined drift schedules54.
Bahrami Dataset54包括完成4臂Bandit Task55的975名参与者。要求参与者在150次试验中选择4个选项。在每个审判中,他们都选择了一个选择并获得了奖励。每个选项的奖励随着时间的流逝以一种被称为不安的强盗的方式漂移,迫使参与者不断探索不同的选项以获得最大的奖励。奖励遵循三个预定义的漂移时间表之一54。
During preprocessing, we removed 57 participants (5.9%) who missed more than 10% of trials. For model fitting, missing trials from other subjects are excluded from the loss calculation.
在预处理期间,我们删除了57名参与者(5.9%),他们错过了超过10%的试验。对于模型拟合,从损失计算中排除了其他受试者的丢失试验。
Original two-stage task
原始的两个阶段任务
In the Gillan dataset56,57, the original version of the two-stage task51 was used to assess goal-directed (model-based) and habitual (model-free) learning in individuals with diverse psychiatric symptoms. In total, 1,961 participants (548 from the first experiment and 1413 from the second experiment) completed the task. In each trial, participants were presented with a choice between two options (A 1 or A 2 ). Each option commonly (70%) led to a particular second-stage state (A 1 →S 1 or A 2 →S 2 ). However, on 30% of ‘rare’ trials, choices led to the alternative second-stage state (A 1 →S 2 or A 2 →S 1 ). In the second-stage states, subjects chose between two options (B 1 /B 2 in S 1 or C 1 /C 2 in S 2 ), each associated with a distinct probability of being rewarded. The reward probabilities associated with each second-stage option drifted slowly and independently over time, remaining within the range of 0.25 to 0.75. To maximize rewards, subjects had to track which second-stage options were currently best as they changed over time.
在Gillan DataSet56,57中,使用两阶段任务的原始版本用于评估具有多种精神病症状的人的目标指导(基于模型)和习惯性(无模型)学习。总共有1,961名参与者(第一个实验的548名,第二个实验的1413个)完成了任务。在每个试验中,向参与者提供了两个选项(1或2个)之间的选择。每个选项通常(70%)导致特定的第二阶段状态(A 1→S 1或2→S 2)。但是,在30%的“罕见”试验中,选择导致了替代的第二阶段状态(A 1→S 2或2→S 1)。在第二阶段,受试者选择了两个选项(在S 1或s 2中的b 1 /b 2中的b 1 /b 2),每个选项都与被奖励的明显概率相关联。随着时间的推移,与每个第二阶段选项相关的奖励概率在缓慢而独立地漂移,保持在0.25至0.75的范围内。为了最大程度地提高奖励,受试者必须跟踪哪些第二阶段选项随着时间的变化,目前最好的选择是最好的。
For model fitting, missing stages or trials from some participants are excluded from the loss calculation.
对于模型拟合,从损失计算中排除了一些参与者的阶段或试验。
Recurrent neural networks
复发性神经网络
Network architectures
网络体系结构
We investigated several architectures, as described below. Our primary goal is to capture the maximum possible behavioural variance with d dynamical variables. While we generally prefer more flexible models due to their reduced bias, such models typically require more data for training, and insufficient data can result in underfitting and poorer performance in comparison to less flexible (simpler) models. Therefore, we aimed to balance data efficiency and model capacity through cross-validation.
如下所述,我们研究了几个架构。我们的主要目标是通过D动态变量捕获最大可能的行为差异。尽管由于偏差的减少,我们通常更喜欢更灵活的模型,但这种模型通常需要更多的数据进行培训,并且与较不灵活的模型相比,数据不足可能导致拟合不足和较差的性能。因此,我们旨在通过交叉验证来平衡数据效率和模型能力。
After finding the best-performing model class, we performed an investigation of the network properties that contributed the most to the successfully explained variance. Analogous to ablation studies, our approach consisted of gradually removing components or adding constraints to the architectures, such as eliminating nonlinearity or introducing symmetric weight constraints. The unaffected predictive performance suggests that the examined components are not essential for the successfully explained variance. If affected, this indicates that these components can contribute to explaining additional behavioural patterns. Following this approach, we can establish connections between architectural components and their corresponding underlying behavioural patterns. The primary objective of this approach is to capture maximum variance with minimal components in the models, resulting in highly interpretable models.
在找到了表现最佳的模型类后,我们对网络属性进行了研究,该属性对成功解释的差异做出了最大的影响。类似于消融研究,我们的方法包括逐渐去除组件或对架构添加约束,例如消除非线性或引入对称重量约束。未受影响的预测性能表明,所检查的组件对于成功解释的方差并不是必需的。如果受影响,这表明这些组件可以有助于解释其他行为模式。遵循这种方法,我们可以在建筑组件及其相应的潜在行为模式之间建立联系。这种方法的主要目的是捕获模型中最小成分的最大差异,从而产生高度可解释的模型。
Recurrent layer
复发层
The neural network models in this paper used the vanilla GRUs in their hidden layers31. The hidden state h t at the beginning of trial t consists of d elements (dynamical variables). The initial hidden state h 1 is set to 0 and h t (t > 1) is updated as follows:
本文中的神经网络模型在其隐藏层中使用了香草grus31。试验开始时的隐藏状态由d元素(动态变量)组成。初始隐藏状态H 1设置为0,H t(t>1)更新如下:
$$\begin{array}{l}{r}_{t}=\sigma ({W}_{ir}{x}_{t-1}+{b}_{ir}+{W}_{hr}{h}_{t-1}+{b}_{hr})\\ {z}_{t}=\sigma ({W}_{iz}{x}_{t-1}+{b}_{iz}+{W}_{hz}{h}_{t-1}+{b}_{hz})\\ {n}_{t}=\tanh ({W}_{in}\,{x}_{t-1}+{b}_{in}+{r}_{t}\odot ({W}_{hn}{h}_{t-1}+{b}_{hn}))\\ {h}_{t}=(1-{z}_{t})\odot {n}_{t}+{z}_{t}\odot {h}_{t-1}\end{array}$$ (1)
$$ \ begin {array} {l} {r} _ {t} = \ sigma({w} _ {ir} {x} {x} _ {t-1}+{b} _ {ir} _ {ir}+{w}+{w}{z} _ {t} = \ sigma({w} _ {iz} {x} _ {t-1}+{b} _ {iz}+{iz}+{w} _ {hz} _ {hz} {hz} {{n} _ {t} = \ tanh({w} _ {in} \,{x} _ {t-1}+{b} _ {b} _ {in}+{r} _ {t} _ {t} \ odot({w} _ {hn} {h} _ {t-1}+{b} _ {hn}))\\ {h} _ {t} =(1- {z} _ {t} _ {t}){h} _ {t-1} \ end {array} $$(1)
where σ is the sigmoid function, ⊙ is the Hadamard (element-wise) product, x t − 1 and h t − 1 are the input and hidden state from the last trial t − 1, and r t , z t and n t are the reset, update and new gates (intermediate variables) at trial t, respectively. The weight matrices W ⋅⋅ and biases b ⋅⋅ are trainable parameters. The d-dimensional hidden state of the network, h t , represents a summary of past inputs and is the only information used to generate outputs.
其中σ是Sigmoid函数,⊙是Hadamard(元素)产品,X T-1和H T-1是上次试验T-1中的输入和隐藏状态,而R t,z T和N T分别是试验时的重置,更新和新的gates和新的gates和new Gates和新的gates(中间变量)。重量矩阵W泼和偏见是可训练的参数。网络H t的D维隐藏状态表示过去输入的摘要,是用于生成输出的唯一信息。
Importantly, the use of GRUs means that the set of d-unit activations fully specifies the network’s internal state, rendering the system Markovian (that is, h t is fully determined by h t − 1 and x t − 1 ). This is in contrast to alternative RNN architectures such as the long short-term memory58, where the use of a cell state renders the system non-Markovian (that is, the output state h t cannot be fully determined by h t − 1 and x t − 1 ).
重要的是,GRU的使用意味着D-UNIT激活集完全指定了网络的内部状态,从而渲染了Markovian系统(即H T完全由H T-1和X T-1完全确定)。这与替代RNN体系结构(例如长期短期内存58)相反,其中细胞状态的使用呈现了系统非马克维亚(即,输出状态H t不能完全由h t-1和x t-1)完全确定)。
To accommodate discrete inputs, we also introduce a modified architecture called switching GRU, where recurrent weights and biases are input-dependent, similar to discrete-latent-variable-dependent switching linear dynamical systems59. In this architecture, the hidden state h t (t > 1) is updated as follows:
为了容纳离散输入,我们还引入了一个称为Switching Gru的修改架构,在该体系结构中,经常性的权重和偏见取决于输入,类似于离散可变量可变性的依赖性开关线性动力学系统59。在此体系结构中,隐藏状态h t(t>1)被更新如下:
$$\begin{array}{l}{r}_{t}=\sigma ({b}_{ir}^{({x}_{t-1})}+{W}_{hr}^{({x}_{t-1})}{h}_{t-1}+{b}_{hr}^{({x}_{t-1})})\\ {z}_{t}=\sigma ({b}_{iz}^{({x}_{t-1})}+{W}_{hz}^{({x}_{t-1})}{h}_{t-1}+{b}_{hz}^{({x}_{t-1})})\\ {n}_{t}=\tanh ({b}_{in}^{({x}_{t-1})}+{r}_{t}\odot ({W}_{hn}^{({x}_{t-1})}{h}_{t-1}+{b}_{hn}^{({x}_{t-1})}))\\ {h}_{t}=(1-{z}_{t})\odot {n}_{t}+{z}_{t}\odot {h}_{t-1}\end{array}$$ (2)
$$ \ begin {array} {l} {r} _ {t} = \ sigma({{b} _ {ir}^{({x} _ {t-1})}+{w} _ {hr}^{({x} _ {x} _ {t-1}}} {{z} _ {t} = \ sigma({b} _ {iz}^{({x} _ {t-1})}}+{w} _ {hz}^{({x} _ {t-1})}} {h} _ {t-1}+{b} _ {hz}^{({x} _ {t-1})})\\{n} _ {t} = \ tanh({b} _ {in}^{({x} _ {t-1})}+{r} _ {t} \ odot({w} _ {hn}^{({x} _ {t-1})} {h} _ {t-1}+{b}{h} _ {t} =(1- {z} _ {t})\ odot {n} _ {t}+{z} _ {t} _ {t} \ odot {h} _ {h} _ {t-1}
where \({W}_{h\cdot }^{({x}_{t-1})}\) and \({b}_{\cdot \cdot }^{({x}_{t-1})}\) are the weight matrices and biases selected by the input x t − 1 (that is, each input x t − 1 induces an independent set of weights W h⋅ and biases b ⋅⋅ ).
其中\({w} _ {h \ cdot}^{({X} _ {t-1})} \)and \({b} _ {\ cdot \ cdot \ cdot}^{({x} _ {x} _ {x} _ {t-1}}}}}} and tupte and int int inct x tuput int in int in in int in int in int in in in in in int- 1诱导独立的权重w H h·和偏见b·)。
For discrete inputs, switching GRUs are a generalization of vanilla GRUs (that is, a vanilla GRU can be viewed as a switching GRU whose recurrent weights do not vary with the input). Generalizations of switching GRUs from discrete to continuous inputs are closely related to multiplicative integration GRUs60.
对于离散输入,开关GRU是香草grus的概括(也就是说,香草gru可以看作是一个开关的gru,其经常性重量不会随输入而变化)。从离散到连续输入切换GRU的概括与乘法整合GRUS60密切相关。
For animal datasets, we found that the switching GRU models performed similarly to the vanilla GRU models for d ≥ 2, but consistently outperformed the vanilla GRU models for d = 1. Therefore, for the results of animal datasets in the main text, we reported the performance of the switching GRU models for d = 1 and the performance of the vanilla GRU models for d ≥ 2. Mathematically, these vanilla GRU models can be directly transformed into corresponding switching GRU models:
对于动物数据集,我们发现,与d≥2的Vanilla Gru模型相似的切换GRU模型,但始终优于D = 1的Vanilla Gru模型。因此,对于主要文本中动物数据集的结果,我们报告了D = 1的Switch gru模型的性能,并直接用于Vanilla Gru Gru Gru disem disem disem disem be disem be disem be disem be disem be disem be disem dist thise thucationally dist thise thucationally dist thise thucationally thuct thism thucty dist thise thucationally dist.这些模型。相应的切换GRU模型:
$$\begin{array}{l}{b}_{i.}^{({x}_{t-1})}\,\leftarrow \,{W}_{i.}\,{x}_{t-1}+{b}_{i.}\\ {b}_{h.}^{({x}_{t-1})}\,\leftarrow \,{b}_{h.}\\ {W}_{h.}^{({x}_{t-1})}\,\leftarrow \,{W}_{h.}\end{array}$$ (3)
$$ \ begin {array} {l} {b} _ {i。}^{({x} _ {t-1})} \,\,\ leftarrow \,{w} _ {i。}{B} _ {\,{w} _ {h。} \ end {array} $$(3)
We also proposed the switching linear neural networks (SLIN), where the hidden state h t (t > 1) is updated as follows:
我们还提出了开关线性神经网络(SLIN),其中隐藏状态h t(t>1)被如下更新:
$${h}_{t}={W}^{({x}_{t-1})}{h}_{t-1}+{b}^{({x}_{t-1})}$$ (4)
$$ {h} _ {t} = {w}^{({x} _ {t-1})} {h} _ {t-1}+{b}+{b}^{({x} _ {x} _ {t-1})}
where \({W}^{({x}_{t-1})}\) and \({b}^{({x}_{t-1})}\) are the weight matrices and biases selected by the input x t − 1 . In some variants, we constrained \({W}^{({x}_{t-1})}\) to be symmetric.
其中\({w}^{({x} _ {t-1})} \)和\({b}^{({x} _ {t-1})} \)是由输入x t t-1选择的重量矩阵和偏差。在某些变体中,我们限制了\({w}^{({x} _ {t-1})} \)为对称。
Input layer
输入层
The network’s input x t consists of the previous action a t − 1 , the previous second-stage state s t − 1 , and the previous reward r t − 1 (but a t = s t in the reversal learning task). In the vanilla GRU networks, the input x t is three-dimensional and projects with linear weights to the recurrent layer. In the switching GRU networks, the input x t is used as a selector variable where the network’s recurrent weights and biases depend on the network’s inputs. Thus, switching GRUs trained on the reversal learning task have four sets of recurrent weights and biases corresponding to all combinations of a t − 1 and r t − 1 , and switching GRUs trained on the two-stage and transition-reversal two-stage tasks have eight sets of recurrent weights and biases corresponding to all combinations of a t − 1 , s t − 1 and r t − 1 .
网络的输入X t包括先前的操作A T-1,先前的第二阶段状态S T-1和先前的奖励r t-1(但在逆转学习任务中A t = S t)。在香草gru网络中,输入x t是三维的,并且具有线性权重的项目与复发层。在开关GRU网络中,输入X t用作选择器变量,其中网络的重复权重和偏见取决于网络的输入。因此,在反转学习任务上接受培训的GRU的切换具有四组反复的重量和偏见,对应于T-1和R T-1的所有组合,并且在两阶段和过渡 - 反转的两阶段任务上进行了训练的GRUS训练的GRU八组重复的权重和偏见对应于所有对应于所有组合的权重,并且对应于所有组合。
Output layer
输出层
The network’s output consists of two units whose activities are linear functions of the hidden state h t . A softmax function (a generalization of the logistic function) is used to convert these activities into a probability distribution (a policy). In the first trial, the network’s output is read out from the initial hidden state h 1 , which has not yet been updated on the basis of any input. For d-unit networks, the network’s output scores were computed either from a fully connected readout layer (that is, \({s}_{t}^{(i)}={\sum }_{j=1}^{d}{\beta }_{i,j}\cdot {h}_{t}^{(j)}\), i = 1, …, d) or from a diagonal readout layer (that is, \({s}_{t}^{(i)}={\beta }_{i}\cdot {h}_{t}^{(i)}\), i = 1, …, d). The output scores are sent to the softmax layer to produce action probabilities.
网络的输出由两个单元组成,其活动是隐藏状态h t的线性函数。SoftMax函数(逻辑函数的概括)用于将这些活动转换为概率分布(策略)。在第一个试验中,从初始隐藏状态H 1读取网络的输出,该输出尚未根据任何输入进行更新。对于D-UNIT网络,从完全连接的读取层(即,\({s} _ {t}^{(i)} = {\ sum} _ {{h} _ {t}^{(j)} \),i = 1,…,d)或从对角线读数层(即,\({s} _ {t} _ {t}^{(i)} = {\ beta} = {\ beta} _}…,D)。输出分数将发送到SoftMax层以产生动作概率。
Network training
网络培训
Networks were trained using the Adam optimizer (learning rate of 0.005) on batched training data with cross-entropy loss, recurrent weight L1-regularization loss (coefficient drawn between 10−5 and 10−1, depending on experiments), and early stop (if the validation loss does not improve for 200 iteration steps). All networks were implemented with PyTorch.
使用ADAM优化器(学习率为0.005)对网络进行培训,这些培训数据具有跨凝性损失,经常性的重量L1调节损失(根据实验,绘制的系数在10-5和10-1之间)和早期停止(如果对200个迭代步骤的验证损失没有改善)。所有网络均通过Pytorch实施。
Classical cognitive models
古典认知模型
Models for the reversal learning task
逆转学习任务的模型
In this task, we implemented one model from the Bayesian inference family and eight models from the model-free family (adopted from34 and12, or constructed from RNN phase portraits).
在此任务中,我们从贝叶斯推理家族和八个模型中实现了一个模型(从34和12通过,或由RNN阶段肖像构建)。
Bayesian inference strategy (d = 1)
贝叶斯推论策略(d = 1)
This model (also known as latent-state) assumes the existence of the latent-state h, with h = i representing a higher reward probability following action A i (state S i ). The probability \({\Pr }_{t}(h=1)\), as the dynamical variable, is first updated via Bayesian inference:
该模型(也称为潜在状态)假定了潜在状态H的存在,而H = i表示动作A I(状态S I)之后的奖励概率更高。概率\({\ pr} _ {t}(h = 1)\)作为动态变量,首先是通过贝叶斯推理更新的:
$${\overline{\Pr }}_{t}(h=1)=\frac{\Pr ({r}_{t-1}| h=1,{s}_{t-1}){\Pr }_{t-1}(h=1)}{\Pr ({r}_{t-1}| h=1,{s}_{t-1}){\Pr }_{t-1}(h=1)+\Pr ({r}_{t-1}| h=2,{s}_{t-1}){\Pr }_{t-1}(h=2)},$$ (5)
$$ {\ OVERLINE {\ pr}} _ {t}(h = 1)= \ frac {\ pr({r} _ {t-1} | h = 1,{s} _ {t-1} _ {t-1}){\ pr}h = 1,{s} _ {t-1}){\ pr} _ {t-1}(h = 1)+\ pr({r} _ {t-1} | h = 2,{s} _ {t-1} _ {t-1}){\ pr}
where the left-hand side is the posterior probability (we omit the conditions for simplicity). The agent also incorporates the knowledge that, in each trial, the latent-state h can switch (for example, from h = 1 to h = 2) with a small probability p r . Thus the probability \({\Pr }_{t}(h)\) reads,
左侧是后验概率(我们省略了简单性的条件)。该代理还结合了以下知识:在每个试验中,潜在h可以用较小的概率p r切换(例如,从h = 1到h = 2)。因此,概率\({\ pr} _ {t}(h)\)读取,
$${\Pr }_{t}(h=1)=(1-{p}_{r}){\overline{\Pr }}_{t}(h=1)+{p}_{r}(1-{\overline{\Pr }}_{t}(h=1)).$$ (6)
$$ {\ pr} _ {t}(h = 1)=(1- {p} _ {r}){\ overline {\ pr}} _ {t}(t}(t}(h = 1)+{p} _ {p} _ {r}(1- {\ overline {\ pr pr}}}}
The action probability is then derived from softmax (βPr t (h = 1), βPr t (h = 2)) with inverse temperature β (β ≥ 0).
然后,该动作概率源自SoftMax(βPRT(H = 1),βPRT(H = 2)),温度为β(β≥0)。
Model-free strategy (d = 1)
无模型策略(d = 1)
This model hypothesizes that the two action values Q t (A i ) are fully anti-correlated (Q t (A 1 ) = −Q t (A 2 )) as follows:
该模型假设两个动作值q t(a i)完全抗相关(q t(a 1)= -q t(a 2))如下:
$$\begin{array}{l}{Q}_{t}({a}_{t-1})\,=\,{Q}_{t-1}({a}_{t-1})+\alpha ({r}_{t-1}-{Q}_{t-1}({a}_{t-1}))\\ {Q}_{t}({\overline{{a}}}_{t-1})\,=\,{Q}_{t-1}({\overline{{a}}}_{t-1})-\alpha ({r}_{t-1}+{Q}_{t-1}({\overline{{a}}}_{t-1})),\end{array}$$ (7)
$$ \ begin {array} {l} {q} _ {t}({a} _ {t-1})\,= \,{q} _ {t-1}({a} _ {a} _ {t-1} _ {t-1})+\ alpha({r} _ {t-1} - {q} _ {t-1}({a} _ {t-1}))\\{Q} _ {t}({\ edrowline {{a}}} _ {t-1})\,= \,{q} _ {t-1}({\ overline {{a}}}}}}}}} _ {t-1} _ {t-1}) - \ alpha({r} _ {t-1}+{q} _ {t-1}({\ overline {{a}}} _ {t-1})),\ end {arnay} $$(7)
where \({\overline{{a}}}_{t-1}\) is the unchosen action, and α is the learning rate (0 ≤ α ≤ 1). We specify the Q t (A 1 ) as the dynamical variable.
其中\({\ edimline {{a}}} _ {t-1} \)是未选择的动作,而α是学习率(0≤α≤1)。我们将Q t(A 1)指定为动力变量。
Model-free strategy (d = 2)
无模型策略(d = 2)
This model hypothesizes that the two action values Q t (A i ), as two dynamical variables, are updated independently:
该模型假设两个动作值q t(a i)作为两个动态变量被独立更新:
$${Q}_{t}({a}_{t-1})={Q}_{t-1}({a}_{t-1})+\alpha ({r}_{t-1}-{Q}_{t-1}({a}_{t-1})).$$ (8)
$$ {q} _ {t}({a} _ {t-1})= {q} _ {t-1}({a} _ {a} _ {t-1})+\ alpha({r} _ {r} _ {t-1} - {t-1} - {q} _} _ {t-1} _ {t-_ {t-1} = 8)
The unchosen action value \({Q}_{t}({\overline{{a}}}_{t-1})\) is unaffected.
未选择的动作值\({q} _ {t}({\ overline {{a}}}} _ {t-1})\)\)不受影响。
Model-free strategy with value forgetting (d = 2)
具有价值遗忘的无模型策略(d = 2)
The chosen action value is updated as in the previous model. The unchosen action value \({Q}_{t}({\overline{{a}}}_{t-1})\), instead, is gradually forgotten:
所选的动作值如前所述更新。未选择的操作值\({q} _ {t}({\ overline {{a}}}} _ {t-1})\)\)被逐渐忘记:
$${Q}_{t}({\overline{{a}}}_{t-1})=D{Q}_{t-1}({\overline{{a}}}_{t-1}),$$ (9)
$$ {q} _ {t}({{\ overline {{a}}} _ {t-1})= d {q} _ {t-1}({\ overline {{a}}}}}}}} _ {t-1}),$$(9),$$(9)
where D is the value forgetting rate (0 ≤ D ≤ 1).
其中d是值遗忘率(0≤d≤1)。
Model-free strategy with value forgetting to mean (d = 2)
具有价值忘记的无模型策略(d = 2)
This model is the ‘forgetful model-free strategy’ proposed in61. The chosen action value is updated as in the previous model. The unchosen action value \({Q}_{t}({\overline{{a}}}_{t-1})\), instead, is gradually forgotten to a initial value (\(\widetilde{V}=1/2\)):
该模型是61 In In In In in 61提出的“健忘的无模型策略”。所选的动作值如前所述更新。取消选择的动作值\({Q} _ {t}({\ overline {{a}}}} _ {t-1})\)\)逐渐忘记到初始值(\(\ widetilde {v}
$${Q}_{t}({\overline{{a}}}_{t-1})=D{Q}_{t-1}({\overline{{a}}}_{t-1})+(1-D)\widetilde{V},$$ (10)
$$ {q} _ {t}({{\ overline {{a}}} _ {t-1})= d {q} _ {t-1}({\ overline {{a}}}}}} _ {{a}} _ {t-1}}
where D is the value forgetting rate (0 ≤ D ≤ 1).
其中d是值遗忘率(0≤d≤1)。
Model-free strategy with the drift-to-the-other rule (d = 2)
与其他规则的无模型策略(d = 2)
This strategy is constructed from the phase diagram of the two-unit RNN. When there is a reward, the chosen action value is updated as follows,
该策略是由两单元RNN的相图构建的。当有奖励时,所选的动作值将更新如下,
$${Q}_{t}({a}_{t-1})={D}_{1}{Q}_{t-1}({a}_{t-1})+1,$$ (11)
$$ {q} _ {t}({a} _ {t-1})= {d} _ {1} {q} {q} _ {t-1}({a} _ {a} _ {t-1})+1,$$ 1,$$(11)
where D 1 is the value drifting rate (0 ≤ D 1 ≤ 1). The unchosen action value is slightly decreased:
其中d 1是值漂移率(0≤d1≤1)。未选择的动作值略有下降:
$${Q}_{t}({\overline{{a}}}_{t-1})={Q}_{t-1}({\overline{{a}}}_{t-1})-b,$$ (12)
$$ {q} _ {t}({{\ overline {{a}}} _ {t-1})= {q} _ {t-1}({\ overline {{a}}}}} _ {t-1} _ {t-1}) -
where b is the decaying bias (0 ≤ b ≤ 1, usually small). When there is no reward, the unchosen action value is unchanged, and the chosen action value drifts to the other:
其中b是腐烂的偏置(0≤b≤1,通常很小)。当没有奖励时,未选择的行动价值将不变,并且所选的动作值向另一个流动:
$${Q}_{t}({a}_{t-1})={Q}_{t-1}({a}_{t-1})+{\alpha }_{0}({Q}_{t-1}({\overline{{a}}}_{t-1})-{Q}_{t-1}({a}_{t-1})),$$ (13)
$$ {q} _ {t}({a} _ {t-1})= {q} _ {t-1}({a} _ {a} _ {t-1})+{\ alpha} _ {0}({q} _ {t-1}({{\ overline {{a}}} _ {t-1}) - {q} _ {t-1}
where α 0 is the drifting rate (0 ≤ α 0 ≤ 1).
其中α0是漂流率(0≤α0≤1)。
For all model-free RL models with d = 2, the action probability is determined by softmax (βQ t (A 1 ), βQ t (A 2 )).
对于所有具有D = 2的无模型RL模型,动作概率由SoftMax(βQT(A 1),βQT(A 2)确定。
Model-free strategy with inertia (d = 2)
惯性的无模型策略(d = 2)
The action values are updated as the model-free strategy (d = 1). The action perseveration (inertia) is updated by:
动作值被更新为无模型策略(d = 1)。动作持久性(惯性)的更新是:
$$\begin{array}{l}{X}_{t}({a}_{t-1})\,=\,{X}_{t-1}({a}_{t-1})+{\alpha }_{{\rm{pers}}}({k}_{{\rm{pers}}}-{X}_{t-1}({a}_{t-1}))\\ {X}_{t}({\overline{{a}}}_{t-1})\,=\,{X}_{t-1}({\overline{{a}}}_{t-1})-{\alpha }_{{\rm{pers}}}({k}_{{\rm{pers}}}+{X}_{t-1}({\overline{{a}}}_{t-1}))\end{array}$$ (14)
$ \ begin {array} {l} {x} _ {t}({a} _ {t-1})\,= \,{x} _ {t-1}({a} _ {a} _ {t-1} _ {t-1})+{\ alpha} _ {{\ rm {pers}}}}}}}({k} _ {{{\ rm {pers}}}}}}}}} - {x} _ {t-1}({a} _ {a} _ {t-1})){x} _ {t}({\ overline {{a}}} _ {t-1})\,= \,{x} _ {t-1}({\ overline {{a}}}}}}}}}} _ {t-1} _ {t-1}) - {\ alpha} _ {{{\ rm {pers}}}}}}({k} _ {{{\ rm {pers}}}}}}+{x} _ {t-1}}
where α pers is the perseveration learning rate (0 ≤ α pers ≤ 1), and k pers is the single-trial perseveration term, affecting the balance between action values and action perseverations.
其中αpers是持续的学习率(0≤αpers≤1),而k pers是单审的持久性项,影响了动作值与动作持久性之间的平衡。
Model-free strategy with inertia (d = 3)
惯性的无模型策略(d = 3)
The action values are updated as the model-free strategy (d = 2). The action perseveration (inertia) is updated by the same rule in the model-free strategy with inertia (d = 2).
动作值被更新为无模型策略(d = 2)。动作持久性(惯性)通过惯性的无模型策略中的相同规则(d = 2)更新。
The action probabilities in all model-free models with inertia are generated via \({\rm{softmax}}\,({\{\beta ({Q}_{t}({A}_{i})+{X}_{t}({A}_{i}))\}}_{i})\). Both the action values and action perseverations are dynamical variables.
通过\({\ rm {softmax}}} \,({\ {\ {\ beta({Q} _ {t}({a} _ {i})+{x} _ {t}(t}({a} _ {i}))\ \}}} _ {i})\)\)。动作值和动作毅力都是动态变量。
Model-free reward-as-cue strategy (d = 8)
无模型奖励策略(d = 8)
This model assumes that the animal considers the combination of the second-stage state s t − 1 and the reward r t − 1 from the trial t − 1 as the augmented state \({{\mathcal{S}}}_{t}\) for trial t. The eight dynamical variables are the values for the two actions at the four augmented states. The action values are updated as follows:
该模型假设动物认为第二阶段态S T-1和试验t-1的奖励r t-1的组合是增强状态\({{{\ Mathcal {s}}}} _ {t} _ {t} \)的组合。八个动态变量是在四个增强状态下的两个动作的值。操作值更新如下:
$${Q}_{t}({{\mathcal{S}}}_{t-1},{a}_{t-1})={Q}_{t-1}({{\mathcal{S}}}_{t-1},{a}_{t-1})+\alpha ({r}_{t-1}-{Q}_{t-1}({{\mathcal{S}}}_{t-1},{a}_{t-1})).$$ (15)
$$ {q} _ {t}({{{\ Mathcal {s}}} _ {t-1},{a} _ {t-1})= {q} _ {t-t-1}}({r} _ {t-1} - {q} _ {t-1}({{{\ Mathcal {s}}}} _ {t-1},{a} _ {a} _ {t-1})。$$(15)
The action probability at trial t is determined by \({\rm{softmax}}\,(\beta {Q}_{t}({{\mathcal{S}}}_{t},{A}_{1}),\beta {Q}_{t}({{\mathcal{S}}}_{t},{A}_{2}))\).
试验t的动作概率由\({\ rm {softmax}}} \,(\ beta {q} _ {t}({{{{\ Mathcal {s}}}}} _ {t} _ {t},{q} _ {t}({{\ Mathcal {s}}}} _ {t},{a} _ {2}))\)\)。
Models for the two-stage task
两阶段任务的模型
We implemented one model from the Bayesian inference family, four models from the model-free family, and four from the model-based family (adopted from refs. 12,34).
我们从贝叶斯推论家族,无模型家族的四个模型和基于模型的家族的四个模型(由参考文献12,34通过)实现了一个模型。
Bayesian inference strategy (d = 1)
贝叶斯推论策略(d = 1)
Same as Bayesian inference strategy (d = 1) in the reversal learning task, except that h = i represents a higher reward probability following state S i (not action A i ).
与逆转学习任务中的贝叶斯推理策略(d = 1)相同,除了h = i代表状态s I(不是动作a i)之后的较高奖励概率。
Model-free strategy (d = 1)
无模型策略(d = 1)
Same as the model-free strategy (d = 1) in the reversal learning task by ignoring the second-stage states s t − 1 .
通过忽略第二阶段状态S t-1,与逆转学习任务中的无模型策略(d = 1)相同。
Model-free Q(1) strategy (d = 2)
无模型Q(1)策略(d = 2)
Same as the model-free strategy (d = 2) in the reversal learning task by ignoring the second-stage states s t − 1 .
通过忽略第二阶段的s t-1,与逆转学习任务中的无模型策略(d = 2)相同。
Model-free Q(0) strategy (d = 4)
无模型Q(0)策略(d = 4)
This model first updates the first-stage action values Q t (a t − 1 ) with the second-stage state values V t − 1 (s t − 1 ):
该模型首先更新具有第二阶段状态值V t-1(s t-1)的第一阶段动作值q t(a t-1):
$${Q}_{t}({a}_{t-1})={Q}_{t-1}({a}_{t-1})+\alpha ({V}_{t-1}({s}_{t-1})-{Q}_{t-1}({a}_{t-1})),$$ (16)
$$ {q} _ {t}({a} _ {t-1})= {q} _ {t-1}({a} _ {a} _ {t-1})+\ alpha({v} _ {t-1}({s} _ {t-1}) - {q} _ {t-1}({a} _ {t-1})),$$(16)
while the unchosen action value \({Q}_{t}({\overline{{a}}}_{t-1})\) is unaffected. Then the second-stage state value V t (s t − 1 ) is updated by the observed reward:
而未选择的动作值\({q} _ {t}({\ overline {{a}}}} _ {t-1})\)\)然后,通过观察到的奖励更新了第二阶段状态值v t(s t-1):
$${V}_{t}({s}_{t-1})={V}_{t-1}({s}_{t-1})+\alpha ({r}_{t-1}-{V}_{t-1}({s}_{t-1})).$$ (17)
$$ {
The four dynamical variables are the two action values and two state values.
四个动态变量是两个动作值和两个状态值。
Model-free reward-as-cue strategy (d = 8)
无模型奖励策略(d = 8)
Same as model-free reward-as-cue strategy (d = 8) in the reversal learning task.
与逆转学习任务中的无模型奖励策略(d = 8)相同。
Model-based strategy (d = 1)
基于模型的策略(d = 1)
In this model, the two state values V t (S i ) are fully anti-correlated (V t (S 1 ) = −V t (S 2 )):
在此模型中,两个状态值v t(s i)完全抗相关(v t(s 1)= -v t(s 2)):
$$\begin{array}{l}{V}_{t}({s}_{t-1})\,=\,{V}_{t-1}({s}_{t-1})+\alpha ({r}_{t-1}-{V}_{t-1}({s}_{t-1}))\\ {V}_{t}({\overline{s}}_{t-1})\,=\,{V}_{t-1}({\overline{s}}_{t-1})-\alpha ({r}_{t-1}+{V}_{t-1}({\overline{s}}_{t-1})),\end{array}$$ (18)
$$ \ begin {array} {l} {v} _ {t}({s} _ {t-1})\,= \,{v} _ {t-1}({s} _ {s} _ {t-1} _ {t-1}))+\ alpha({r} _ {t-1} - {v} _ {t-1}({s} _ {t-1}))\\{v} _ {t}({\ overline {s}} _ {t-1})\,= \,{v} _ {t-1}({\ overline {s}}} _ {t-1} _ {t-1}) - \ alpha({r} _ {t-1}+{v} _ {t-1}({\ overline {s}} _ {t-1})),\ end end {array} $$(18)
where \({\bar{s}}_{t-1}\) is the unvisited state. The dynamical variable is the state value V t (S 1 ).
其中\({\ bar {s}} _ {t-1} \)是未访问的状态。动态变量是状态值v t(s 1)。
Model-based strategy (d = 2)
基于模型的策略(d = 2)
The visited state value is updated:
访问的状态价值已更新:
$${V}_{t}({s}_{t-1})={V}_{t-1}({s}_{t-1})+\alpha ({r}_{t-1}-{V}_{t-1}({s}_{t-1})).$$ (19)
$$ {
The unvisited state value is unchanged. The two dynamical variables are the two state values.
未访问的状态价值没有变化。两个动态变量是两个状态值。
Model-based strategy with value forgetting (d = 2)
具有价值遗忘的基于模型的策略(d = 2)
The visited state value is updated as in the previous model. The unvisited state value is gradually forgotten:
访问的状态值如前所述更新。未访问的状态价值逐渐被遗忘:
$${V}_{t}({\bar{s}}_{t-1})=D{V}_{t-1}({\bar{s}}_{t-1}),$$ (20)
$$ {
where D is the value forgetting rate (0 ≤ D ≤ 1).
其中d是值遗忘率(0≤d≤1)。
For all model-based RL models, the action values at the first stage are directly computed using the state-transition model:
对于所有基于模型的RL模型,第一阶段的动作值是使用状态转换模型直接计算的:
$${Q}_{t}^{{\rm{m}}{\rm{b}}}({A}_{i})=\sum _{j}Pr({S}_{j}|{A}_{i}){V}_{t}({S}_{j}),$$ (21)
$$ {q} _ {t}^{{\ rm {m}}} {\ rm {b}}}}}}}}}}({a} _ {i})= \ sum_ {j} pr({s} _ {j} | {a} _ {i}){v} _ {t}({s} _ {j}),$$(21)
where Pr(S j ∣A i ) is known. The action probability is determined by \(\text{softmax}\,(\beta {Q}_{t}^{{\rm{m}}{\rm{b}}}({A}_{1}),\beta {Q}_{t}^{{\rm{m}}{\rm{b}}}({A}_{2}))\).
pr(s j a i)的地方。动作概率由\(\ text {softmax} \,(\ beta {q} _ {t} _ {t}^{{\ rm {\ rm {m}} {\ rm {b}}}}}}}}}}}}}}}}}}}{q} _ {t}^{{\ rm {m}}} {\ rm {b}}}}}}}({a} _ {2}))\)\)。
Model-based mixture strategy (d = 2)
基于模型的混合策略(D = 2)
This model is a mixture of the model-free strategy (d = 1) and the model-based strategy (d = 1). The net action values are determined by:
该模型是无模型策略(d = 1)和基于模型的策略(d = 1)的混合物。净动作值由:
$${Q}_{t}^{{\rm{n}}{\rm{e}}{\rm{t}}}({A}_{i})=(1-w){Q}_{t}^{{\rm{m}}{\rm{f}}}({A}_{i})+w{Q}_{t}^{{\rm{m}}{\rm{b}}}({A}_{i}),$$ (22)
$$ {q} _ {t}^{{\ rm {n}} {\ rm {e}} {\ rm {t}}}}}}}}}({a} _} _ {i} _ {i}(i})=(1-w)=(1-w)m {m}} {\ rm {f}}}}}({a} _ {i})+w {q} _ {t}^{{\ rm {\ rm {m}} {\ rm {\ rm {b}}}}}}}}}}}}(a} _} _} _ {a} _ {i} _ {i} _ {i}),$$(22)
where w controls the strength of the model-based component. The action probabilities are generated via \(\text{softmax}\,(\beta {Q}_{t}^{{\rm{net}}}({A}_{1}),\beta {Q}_{t}^{{\rm{net}}}({A}_{2}))\). \({Q}_{t}^{{\rm{mf}}}({A}_{1})\) and V t (S 1 ) are the dynamical variables.
W控制基于模型的组件的强度。动作概率通过\(\ text {softmax} \,(\ beta {q} _ {t} _ {t}^{{\ rm {net}}}}}}}({a} _ {1}),\ beta,\ beta{q} _ {t}^{{\ rm {net}}}}}({a} _ {2}))\)\)。\({q} _ {t}^{{\ rm {mf}}}}}}}({a} _ {1})\)和v t(s 1)是动态变量。
Models for the transition-reversal two-stage task
过渡 - 反转两阶段任务的模型
For this task, we further include cognitive models proposed in ref. 11. We first describe different model components (ingredients) and corresponding numbers of dynamical variables, and then specify the components employed in each model.
对于此任务,我们进一步包括参考文献中提出的认知模型。11。我们首先描述不同的模型组件(成分)和相应的动态变量数量,然后指定每个模型中使用的组件。
Second-stage state value component
第二阶段状态值组件
The visited state value is updated:
访问的状态价值已更新:
$${V}_{t}({s}_{t-1})={V}_{t-1}({s}_{t-1})+{\alpha }_{Q}({r}_{t-1}-{V}_{t-1}({s}_{t-1})).$$ (23)
$ 4 {} _ {q}({r} _ {t-1} - {v} _ {t-1}({s} _ {t-1}))。$$(23)
The unvisited state value \({V}_{t}({\bar{s}}_{t-1})\) is either unchanged or gradually forgotten with f Q as the value forgetting rate. This component requires two dynamical variables.
未访问的状态值\({v} _ {t}({\ bar {s}} _ {t-1})\)是不变的,要么以f q逐渐遗忘,作为价值遗忘率。该组件需要两个动态变量。
Model-free action value component
无模型的动作值组件
The first-stage action values \({Q}_{t}^{{\rm{mf}}}({a}_{t-1})\) are updated by the second-stage state values V t − 1 (s t − 1 ) and the observed reward:
第二阶段的状态值V t-1(S t-1)和观察到的奖励:
$${Q}_{t}^{{\rm{mf}}}({a}_{t-1})={Q}_{t-1}^{{\rm{mf}}}({a}_{t-1})+\alpha (\lambda {r}_{t-1}+(1-\lambda ){V}_{t-1}({s}_{t-1})-{Q}_{t-1}^{{\rm{mf}}}({a}_{t-1})),$$ (24)
$$ {q} _ {t}^{{\ rm {\ rm {mf}}}}}({a} _ {t-1})= {q} _ {t-1}^{{\ rm {\ rm {mf}}}}}}}}}}}(a} _} _} _ {a} _ {t-1} _ {t-1} _ {t-1}){r} _ {t-1}+(1- \ lambda){v} _ {t-1}({s} _ {t-1}) - {q} _ {t-1}^{t-1}^{{\ rm {mf}}}}}}
where λ is the eligibility trace. The unchosen action value \({Q}_{t}^{{\rm{mf}}}({\overline{{a}}}_{t-1})\) is unaffected or gradually forgotten with f Q as the value forgetting rate. This component requires two dynamical variables.
其中λ是资格迹线。未选择的动作值\({q} _ {t}^{{\ rm {\ rm {mf}}}}}}}({\ edimline {{a}}} _ {t-1})\)\)是未受到的,或者逐渐被F q逐渐遗忘,因为价值忘记了。该组件需要两个动态变量。
Model-based component
基于模型的组件
The action-state-transition probabilities are updated as:
动作状态 - 转变概率被更新为:
$$\begin{array}{r}{P}_{t}({s}_{t-1}| {a}_{t-1})={P}_{t-1}({s}_{t-1}| {a}_{t-1})+{\alpha }_{T}(1-{P}_{t-1}({s}_{t-1}| {a}_{t-1}))\\ {P}_{t}({\overline{s}}_{t-1}| {a}_{t-1})={P}_{t-1}({\overline{s}}_{t-1}| {a}_{t-1})+{\alpha }_{T}(0-{P}_{t-1}({\overline{s}}_{t-1}| {a}_{t-1})),\end{array}$$ (25)
$$ \ begin {array} {r} {p} _ {t}({s} _ {t-1} | {a} _ {t-1})= {p} _ {t-1} _ {t-1}({s} _} _ {s} _ {t-1} _ {t-1} | {a} | {a} _ {a} _ {t-1}} _ {t}(1- {p} _ {t-1}({s} _ {t-1} | {a} _ {t-1}))\\ {p} _ {t}({\ overline {s}} _ {s} _ {t-_ {t-1} |{a} _ {t-1})= {p} _ {t-1}({\ overline {s}} _ {t-1} | {a} _} _ {t-1})+{\ alpha} _ {t}(0- {p} _ {t-1}({\ overline {s}} _ {t-1} | {a} _ {t-1})),\ end {array {array} $$(25)
where α T is the transition probability learning rate. For the unchosen action, the action-state-transition probabilities are either unchanged or forgotten:
其中αT是过渡概率学习率。对于未选择的行动,动作状态 - 转变概率是不变的,要么被遗忘:
$$\begin{array}{l}{P}_{t}({s}_{t-1}| {\overline{{a}}}_{t-1})={P}_{t-1}({s}_{t-1}| {\overline{{a}}}_{t-1})+{f}_{T}(0.5-{P}_{t-1}({s}_{t-1}| {\overline{{a}}}_{t-1}))\\ {P}_{t}({\overline{s}}_{t-1}| {\overline{{a}}}_{t-1})={P}_{t-1}({\overline{s}}_{t-1}| {\overline{{a}}}_{t-1})+{f}_{T}(0.5-{P}_{t-1}({\overline{s}}_{t-1}| {\overline{{a}}}_{t-1})),\end{array}$$ (26)
$$ \ begin {array} {l} {p} _ {t}({s} _ {t-1} | {\ overline {{a}}}} _ {t-1} _ {t-1})= {p} _ {p} _ {t-1}(s}}(s} {s} _ {T-1 _ {T-1}}{\ Overline {{{a}}} _ {t-1})+{f} _ {t}(0.5- {p} _ {t-1}}({s} _ {t-1} _ {t-1} |{p} _ {t}({\ overline {s}} _ {t-1} | {\ overline {{a}}} _ {t-1})= {p} _ {p} _ {t-1}({t-1}){\ Overline {{{a}}} _ {t-1})+{f} _ {t}(0.5- {p} _ {t-1}({\ overline {s}}}} _ {s}} _ {t-1}(26)
where f T is the transition probability forgetting rate.
其中f t是过渡概率忘记率。
The model-based action values at the first stage are directly computed using the learned state-transition model:
第一阶段的基于模型的动作值是使用学习的状态转变模型直接计算的:
$${Q}_{t}^{{\rm{mb}}}({A}_{i})=\sum _{j}{P}_{t}({S}_{j}| {A}_{i}){V}_{t}({S}_{j}).$$ (27)
$$ {q} _ {t}^{{\ rm {\ rm {mb}}}}({a} _ {i})= \ sum _ {j} {j} {p} _ {t}{a} _ {i}){v} _ {t}({s} _ {j})。$$(27)
This component requires two dynamical variables (P t (S 1 ∣A 1 ) and P t (S 1 ∣A 2 )), since other variables can be directly inferred.
由于可以直接推断出其他变量,因此该组件需要两个动态变量(p t(s 1°1)和p t(s 1°2))。
Motor-level model-free action component
无运动级的无模型动作组件
Due to the apparatus design in this task11, it is proposed that the mice consider the motor-level actions \({a}_{t-1}^{{\rm{m}}{\rm{o}}}\), defined as the combination of the last-trial action a t − 1 and the second-stage state s t−2 before it. The motor-level action values \({Q}_{t}^{{\rm{m}}{\rm{o}}}({a}_{t-1}^{{\rm{m}}{\rm{o}}})\) are updated as:
由于此任务中的设备设计,因此建议小鼠考虑电动机级别的动作\({a} _ {t-1}^{{\ rm {M}} {\ rm {m}} {\ rm {rom {o}}}}} \),被定义为最后一个t-1和第二st-t-t-1 s的组合。电机级操作值\({q} _ {t}^{{\ rm {\ rm {m}}} {\ rm {o}}}}}}}}}}}}({a} _ {t-1}}^{{\ rm {\ rm {m}}}}
$${Q}_{t}^{{\rm{m}}{\rm{o}}}({a}_{t-1}^{{\rm{m}}{\rm{o}}})={Q}_{t-1}^{{\rm{m}}{\rm{o}}}({a}_{t-1}^{{\rm{m}}{\rm{o}}})+\alpha (\lambda {r}_{t-1}+(1-\lambda ){V}_{t-1}({s}_{t-2})-{Q}_{t-1}^{{\rm{m}}{\rm{o}}}({a}_{t-1}^{{\rm{m}}{\rm{o}}})),$$ (28)
$$ {q} _ {t}^{{{\ rm {m}} {\ rm {o}}}}}}}}}}}}}({a} _ {t-1}^{\ rm {\ rm {m {m {m}}_ {t-1}^{{\ rm {m}}} {\ rm {o}}}}}}({a} _ {t-1}^{{\ rm {m}}} {\ rm {m}} {\ rm {o rm {o}}}}}}}}}}}})+\ alpha(\ lambda {r} _ {t-1}+(1- \ lambda){v} _ {t-1}({s} _ {t-2}) - {q} _ {t-1}^{{\ rm {m {m {m}} {\ rm {o}}}}({a} _ {t-1}^{{\ rm {m}}} {\ rm {o}}})),$$(28)
where λ is the eligibility trace. The unchosen motor-level action value \({Q}_{t}^{{\rm{m}}{\rm{o}}}\) is unaffected or gradually forgotten with f Q as the value forgetting rate. This component requires four dynamical variables (four motor-level actions).
其中λ是资格迹线。未选择的电动机级操作值\({q} _ {t}^{{\ rm {m}}} {\ rm {o}}} \)不受影响或逐渐被f q逐渐遗忘,因为值忘记了。该组件需要四个动态变量(四个电动机级别的动作)。
Choice perseveration component
选择持久性组件
The single-trial perseveration \({\widetilde{X}}_{t-1}^{{\rm{cp}}}\) is set to −0.5 for a t − 1 = A 1 and 0.5 for a t − 1 = A 2 . The multi-trial perseveration \({Q}_{t-1}^{{\rm{c}}{\rm{p}}}\) (exponential moving average of choices) is updated as:
单端持久性\({\ widetilde {x}} _ {t-1}^{{\ rm {cp}}} \)将t - 1 = a 1和0.5设置为-0.5,对于A 1和0.5,对于A T - 1和0.5。多批判性持久性\({q} _ {t-1}^{{\ rm {c}}} {\ rm {p}}}} \)(选择的指数移动平均值)已更新为::
$${X}_{t}^{{\rm{cp}}}={X}_{t-1}^{{\rm{cp}}}+{\alpha }_{c}({\widetilde{X}}_{t-1}^{{\rm{cp}}}-{X}_{t-1}^{{\rm{cp}}}),$$ (29)
$$ {x} _ {t}^{{\ rm {cp}}}} = {x} _ {t-1}^{{\ rm {cp}}}}}}+{\ alpha} _ {c}({\ widetilde {x}} _ {t-1}^{{\ rm {cp}}}}}} - {x} _ {t-1}}^{{\ rm {cp}}}}}}}}}}}}}}}}),$$(29)
where α c is the choice perseveration learning rate. In some models, the α c is less than 1, so one dynamical variable is required; while in some other models, the α c is fixed to 1, suggesting that it is reduced to the single-trial perseveration and no dynamical variable is required.
其中αC是选择持久性学习率。在某些模型中,αC小于1,因此需要一个动态变量。虽然在其他一些模型中,αC固定为1,这表明它被降低为单审判的持久性,并且不需要动态变量。
Motor-level choice perseveration component
电动机选择持久性组件
The multi-trial motor-level perseveration \({X}_{t-1}^{{\rm{mocp}}}({s}_{t-2})\) is updated as:
多试的电机级持久性\({x} _ {t-1}^{{\ rm {\ rm {mocp}}}}}}}}}}({s} _ {t-2})\)被更新为:
$${X}_{t}^{{\rm{mocp}}}({s}_{t-2})={X}_{t-1}^{{\rm{mocp}}}({s}_{t-2})+{\alpha }_{m}({\widetilde{X}}_{t-1}^{{\rm{cp}}}-{X}_{t-1}^{{\rm{mocp}}}({s}_{t-2})),$$ (30)
$$ {x} _ {t}^{{\ rm {\ rm {mocp}}}}}({s} _ {t-2})= {x} _ {t-1}^{\ rm {\ rm {mocp}}}}}}}}}}}}}(s}}(s} _ {s} _ {t-t-_ {t-t-2} al {} _ {m}({\ widetilde {x}} _ {t-1}^{{{\ rm {cp}}}}}} - {x} _ {t-1}^}^{{\ rm {\ rm {mocp}}}}}
where α m is the motor-level choice perseveration learning rate. This component requires two dynamical variables.
其中αM是运动水平的选择持久学习率。该组件需要两个动态变量。
Action selection component
动作选择组件
The net action values are computed as follows:
净动作值计算如下:
$${Q}_{t}^{{\rm{net}}}({A}_{i})={G}^{{\rm{mf}}}{Q}_{t}^{{\rm{mf}}}({A}_{i})+{G}^{{\rm{mo}}}{Q}_{t}^{{\rm{mo}}}({A}_{i},{s}_{t-1})+{G}^{{\rm{mb}}}{Q}_{t}^{{\rm{mb}}}({A}_{i})+{X}_{t}({A}_{i}),$$ (31)
$$ {q} _ {t}^{{\ rm {net}}}}}}}({a} _ {i})= {g}q} _ {t}^{{\ rm {mf}}}}}}}({a} _ {i})+{g}^{{\ rm {mo {mo}}}} {q} {q} _ {t}^{{{\ rm {mo}}}}({a} _ {i},{s} _ {t-1})+{g}^{\ rm {mb {mb}}} {q} _ {t}^{{\ rm {mb}}}}}}}({a} _ {i})+{x} _ {t}(t}({a} _ {i {i}),$$(31)
where Gmf, Gmo and Gmb are model-free, motor-level model-free and model-based inverse temperatures, respectively, and X t (A i ) is:
如果GMF,GMO和GMB分别为无模型,无运动水平和基于模型的反向温度,而X T(A I)为:
$$\begin{array}{l}{X}_{t}({A}_{1})=0\\ {X}_{t}({A}_{2})={B}_{c}+{B}_{r}{\widetilde{X}}_{t-1}^{{\rm{s}}}+{P}_{c}{X}_{t}^{{\rm{cp}}}+{P}_{m}{X}_{t}^{{\rm{mocp}}}({s}_{t-1}),\end{array}$$ (32)
$$ \ begin {array} {l} {x} _ {t}({a} _ {1})= 0 \\{x} _ {t}({a} _ {2})= {b} _ {c}+{b} _ {r} {r} {\ widetilde {x}}} _ {{x} _ {t}^{{\ rm {cp}}}}+{p} _ {m} {x} {x} _ {t}^{{\ rm {\ rm {mocp}}}}}}}}}}}({s} _ {s} _ {t-1} _ {t-1})(32)
where B c (bias), B r (rotation bias), P c , P m are weights controlling each component, and \({\widetilde{X}}_{t-1}^{s}\) is −0.5 for s t − 1 = S 1 and 0.5 for s t − 1 = S 2 .
其中b c(偏见),b r(旋转偏见),p c,p m是控制每个组件的权重,而\({\ widetilde {x}} _ {t-1}^{s}^{s} \)为-0.5,对于s t-1 = s = s 1和0.5,对于s t-1 = s = s t = s t - 1和0.5。
The action probabilities are generated via \(\text{softmax}\,({Q}_{t}^{{\rm{net}}}({A}_{1}),\) \({Q}_{t}^{{\rm{net}}}({A}_{2}))\).
操作概率是通过\(\ text {softmax} \,({q} _ {t}^{{\ rm {net}}}}}}({a} _ {1}),\)\({Q} _ {t}^{{\ rm {net}}}}}}({a} _ {2}))\)\)。
Model-free strategies
无模型策略
We include five model-free RL models:
我们包括五种无模型RL模型:
(1) the model-free strategy (d = 1) same as the two-stage task; (2) the model-free Q(1) strategy (d = 2) same as the two-stage task; (3) state value [2] + model-free action value [2] + bias [0] + rotation bias [0] + single-trial choice perseveration [0]; (4) state value [2] + model-free action value with forgetting [2] + bias [0] + rotation bias [0] + single-trial choice perseveration [0]; (5) state value [2] + model-free action value with forgetting [2] + motor-level model-free action value with forgetting [4] + bias [0] + rotation bias [0] + multi-trial choice perseveration [1] + multi-trial motor-level choice perseveration [2].
(1)与两阶段任务相同的无模型策略(d = 1);(2)无模型Q(1)策略(d = 2)与两阶段任务相同;(3)状态值[2] +无模型的动作值[2] +偏差[0] +旋转偏置[0] +单审选择持久性[0];(4)状态值[2] +遗忘[2] +偏差[0] +旋转偏置[0] +单审选择持久性[0];(5)状态值[2] +带有遗忘[2] +电动机级模型的动作值的无模型动作值,忘记[4] +偏差[0] +旋转偏见[0] +多试验选择持久性[1] +多试验电动机级别选择持久性[2]。
Here, we use the format of ‘model component [required number of dynamical variables]’ (more details in ref. 11).
在这里,我们使用“模型组件[所需的动态变量数量)的格式(参考文献11中的更多详细信息)。
Model-based strategies
基于模型的策略
We include 12 model-based RL models:
我们包括12种基于模型的RL模型:
(1) state value [2] + model-based [2] + bias [0] + rotation bias [0] + single-trial choice perseveration [0]; (2) state value [2] + model-free action value [2] + model-based [2] + bias [0] + rotation bias [0] + single-trial choice perseveration [0]; (3) state value [2] + model-based with forgetting [2] + bias [0] + rotation bias [0] + single-trial choice perseveration [0]; (4) state value [2] + model-free action value with forgetting [2] + model-based with forgetting [2] + bias [0] + rotation bias [0] + single-trial choice perseveration [0]; (5) state value [2] + model-free action value with forgetting [2] + model-based [2] + bias [0] + rotation bias [0] + single-trial choice perseveration [0]; (6) state value [2] + model-free action value [2] + model-based [2] + bias [0] + rotation bias [0] + multi-trial choice perseveration [1]; (7) state value [2] + model-free action value with forgetting [2] + model-based with forgetting [2] + bias [0] + rotation bias [0] + multi-trial choice perseveration [1]; (8) state value [2] + model-free action value with forgetting [2] + model-based [2] + bias [0] + rotation bias [0] + multi-trial choice perseveration [1]; (9) state value [2] + model-free action value with forgetting [2] + model-based with forgetting [2] + bias [0] + rotation bias [0] + multi-trial motor-level choice perseveration [2]; (10) state value [2] + model-based with forgetting [2] + bias [0] + rotation bias [0] + multi-trial choice perseveration [1] + multi-trial motor-level choice perseveration [2]; (11) state value [2] + model-free action value with forgetting [2] + model-based with forgetting [2] + bias [0] + rotation bias [0] + multi-trial choice perseveration [1] + multi-trial motor-level choice perseveration [2]; (12) state value [2] + model-free action value with forgetting [2] + model-based with forgetting [2] + motor-level model-free action value with forgetting [4] + bias [0] + rotation bias [0] + multi-trial choice perseveration [1] + multi-trial motor-level choice perseveration [2].
(1)状态值[2] +基于模型的[2] +偏差[0] +旋转偏置[0] +单审选择持久性[0];(2)状态值[2] +无模型的动作值[2] +基于模型[2] +偏差[0] +旋转偏置[0] +单试选择持久性[0];(3)状态值[2] +基于模型的遗忘[2] +偏差[0] +旋转偏置[0] +单审选择持久性[0];(4)遗忘[2] +基于遗忘的模型[2] +偏差[0] +旋转偏见[0] +单审选择持久性[0];(5)状态值[2] +带有遗忘[2] +基于模型的[2] +偏差[0] +旋转偏置[0] +单审判持续[0]的无模型动作值[0];(6)状态值[2] +无模型动作值[2] +基于模型[2] +偏差[0] +旋转偏置[0] +多试验选择持久性[1];(7)遗忘[2] +基于模型的遗忘[2] +偏差[0] +旋转偏差[0] +多试验选择持久性[1]的状态值[2] +遗忘[2] +基于模型的无模型动作值[1];(8)状态值[2] +带有遗忘[2] +基于模型的[2] +偏差[0] +旋转偏置[0] +多试验选择持久性[1]的无模型动作值[1];(9)状态值[2] +遗忘[2] +基于模型的无模型动作值,而遗忘[2] +偏差[0] +旋转偏见[0] +多试件电动机级别选择持久性[2];(10)状态值[2] +基于遗忘[2] +偏差[0] +旋转偏置[0] +多试验选择持久性[1] +多试验电动机级别选择持久性[2];(11)状态值[2] +带有遗忘[2] +基于模型的无模型动作值,而遗忘[2] +偏差[0] +旋转偏见[0] +多试验选择持久性[1] +多试验电动机级别选择持久性[2];(12)状态值[2] +带有忘记[2] +基于模型的无模型动作值,而忘记[2] +电动机级的无模型动作值,而忘记[4] +偏差[0] +旋转偏见[0] +多验证perseveration [1] +多验证电动机级别的运动级别选择perseveration [2]。
Here, we use the format of model component [required number of dynamical variables] (more details in ref. 11).
在这里,我们使用模型组件的格式[所需的动态变量数量](参考文献11中的更多详细信息)。
Models for the three-armed reversal learning task
三臂逆转学习任务的模型
We implemented four models (n = 3 actions) from the model-free family, one of which is constructed from the strategies discovered by the RNN.
我们从无模型家族中实现了四个模型(n = 3个动作),其中一个是根据RNN发现的策略构建的。
Model-free strategy (d = n)
无模型策略(d = n)
This model hypothesizes that each action value Q t (A i ), as a dynamical variable, is updated independently. The chosen action value is updated by:
该模型假设每个动作值q t(a i)作为动态变量,都是独立更新的。选定的操作值通过以下方式更新:
$${Q}_{t}({a}_{t-1})={Q}_{t-1}({a}_{t-1})+\alpha ({r}_{t-1}-{Q}_{t-1}({a}_{t-1})).$$ (33)
$$ {q} _ {t}({a} _ {t-1})= {q} _ {t-1}({a} _ {a} _ {t-1})+\ alpha({r} _ {r} _ {t-1} - {t-1} - {q} _ {q} _ {t-1} _ {t-1} =
The unchosen action values Q t (A j ) (A j ≠ a t − 1 ) are unaffected.
未选择的动作值q t(a j)(a j≠a t -1)不受影响。
Model-free strategy with value forgetting (d = n)
具有价值遗忘的无模型策略(d = n)
The chosen action value is updated as in the previous model. The unchosen action value Q t (A j ) (A j ≠ a t − 1 ), instead, is gradually forgotten:
所选的动作值如前所述更新。未选择的动作值q t(a j)(a j≠a t -1)被逐渐忘记:
$${Q}_{t}({A}_{j})=D{Q}_{t-1}({A}_{j}),$$ (34)
$$ {q} _ {t}({a} _ {j})= d {q} _ {t-1}({a} _ {j}),$$(34)
where D is the value forgetting rate (0 ≤ D ≤ 1).
其中d是值遗忘率(0≤d≤1)。
Model-free strategy with value forgetting and action perseveration (d = 2n)
具有价值遗忘和行动持久性的无模型策略(d = 2n)
The action values are updated as the model-free strategy with value forgetting. The chosen action perseveration is updated by:
动作值被更新为具有价值遗忘的无模型策略。选定的操作持久性通过以下方式更新:
$${X}_{t}({a}_{t-1})={D}_{{\rm{pers}}}{X}_{t-1}({a}_{t-1})+{k}_{{\rm{pers}}},$$ (35)
$$ {x} _ {t}({a} _ {t-1})= {d} _ {{{\ rm {pers}}}} {x} {x} _ {t-1}({a}
and the unchosen action perseverations are updated by:
并且未选择的行动持久性通过以下方式更新:
$${X}_{t}({A}_{j})={D}_{{\rm{pers}}}{X}_{t-1}({A}_{j}),$$ (36)
$$ {x} _ {t}({a} _ {j})= {d} _ {{{\ rm {pers}}}} {x} _ {t-1}
where D pers is the perseveration forgetting rate (0 ≤ D pers ≤ 1), and k pers is the single-trial perseveration term, affecting the balance between action values and action perseverations.
其中d pers是持续的遗忘率(0≤dpers≤1),而k pers是单审的持久性项,影响了动作值和动作持久性之间的平衡。
Model-free strategy with unchosen value updating and reward utility (d = n)
不选择更新和奖励实用程序的无模型策略(d = n)
This model is constructed from the strategy discovered by the RNN (see Supplementary Results 1.4). It assumes that the reward utility U(r) (equivalent to the preference setpoint) is different in four cases (corresponding to four free parameters): no reward for chosen action (U c (0)), one reward for chosen action (U c (1)), no reward for unchosen action (U u (0)), and one reward for chosen action (U u (1)).
该模型是根据RNN发现的策略构建的(请参阅补充结果1.4)。It assumes that the reward utility U(r) (equivalent to the preference setpoint) is different in four cases (corresponding to four free parameters): no reward for chosen action (U c (0)), one reward for chosen action (U c (1)), no reward for unchosen action (U u (0)), and one reward for chosen action (U u (1)).
The chosen action value is updated by:
选定的操作值通过以下方式更新:
$${Q}_{t}({a}_{t-1})={Q}_{t-1}({a}_{t-1})+{\alpha }_{c}({U}_{c}({r}_{t-1})-{Q}_{t-1}({a}_{t-1})).$$ (37)
$$ {q} _ {t}({a} _ {t-1})= {q} _ {t-1}({a} _ {a} _ {t-1})+{\ alpha} _ {c}({u} _ {c}({r} _ {t-1})) - {q} _ {t-1}({a} _} _ {t-1}))。$$(37)
The unchosen action value Q t (A j ) (A j ≠ a t − 1 ) is updated by:
未选择的动作值q t(a j)(a j≠a t -1)由以下更新:
$${Q}_{t}({A}_{j})={Q}_{t-1}({A}_{j})+{\alpha }_{u}({U}_{u}({r}_{t-1})-{Q}_{t-1}({A}_{j})).$$ (38)
$$ {q} _ {t}({a} _ {j})= {q} _ {t-1}({a} _ {j})+{\ alpha} _ {u}({u} _ {u}({r} _ {t-1})) - {q} _ {t-1}(t-1}({a} _ {j}))。$ 4(38)
The action probabilities for these models are generated via \({\rm{softmax}}\,({\{\beta ({Q}_{t}({A}_{i})+{X}_{t}({A}_{i}))\}}_{i})\) (X t = 0 for models without action perseverations). Both the action values and action perseverations are dynamical variables.
这些模型的动作概率是通过\({\ rm {softmax}}} \,({{\ {\ beta({q} _ {t}({a} _} _ {a} _ {i} _ {i})对于没有动作持久性的模型,t = 0。动作值和动作毅力都是动态变量。
Models for the four-armed drifting bandit task
四臂漂流匪徒任务的型号
We implemented five models (n = 4 actions) from the model-free family, two of which are constructed from the strategies discovered by the RNN.
我们从无模型家族中实现了五个模型(n = 4个动作),其中两个是根据RNN发现的策略构建的。
Model-free strategy (d = n)
无模型策略(d = n)
This model is the same as the model-free strategy in the three-armed reversal learning task.
该模型与三臂逆转学习任务中的无模型策略相同。
Model-free strategy with value forgetting (d = n)
具有价值遗忘的无模型策略(d = n)
This model is the same as the model-free strategy with value forgetting in the three-armed reversal learning task.
该模型与无模型策略相同,在三臂逆转学习任务中遗忘了价值。
Model-free strategy with value forgetting and action perseveration (d = 2n)
具有价值遗忘和行动持久性的无模型策略(d = 2n)
This model is the same as the model-free strategy with value forgetting and action perseveration in the three-armed reversal learning task.
该模型与在三臂逆转学习任务中具有价值遗忘和行动持久性的无模型策略相同。
Model-free strategy with unchosen value updating and reward reference point (d = n)
具有未选择值更新和奖励参考点(d = n)的无模型策略(d = n)
This model is constructed from the strategy discovered by the RNN (see Supplementary Results 1.5). It assumes that the reward utility U(r) is different for chosen action (U c (r) = β c (r − R c )) and for unchosen action (U u (r) = β u (r − R u )), where β c and β u are reward sensitivities, and R c and R u are reward reference points.
该模型是根据RNN发现的策略构建的(请参阅补充结果1.5)。它假设所选作用(u c(r)=βC(r -r c))和未选择的动作(u u(r)=βu(r -r -r u))的奖励效用u(r)是不同的,其中βc和βu是奖励敏感性,r c和r u是奖励参考点。
The chosen action value is updated by:
选定的操作值通过以下方式更新:
$${Q}_{t}({a}_{t-1})=(1-{\alpha }_{c}){Q}_{t-1}({a}_{t-1})+{U}_{c}({r}_{t-1}),$$ (39)
$$ {q} _ {t}({a} _ {t-1})=(1 - {\ alpha} _ {c}){q} _ {t-t-t-t-_}({a} _} _ {a} _ {t-1})
where 1 − α c is the decay rate for chosen actions. The unchosen action value Q t (A j ) (A j ≠ a t − 1 ) is updated by:
其中1 -αC是所选作用的衰减率。未选择的动作值q t(a j)(a j≠a t -1)由以下更新:
$${Q}_{t}({A}_{j})=(1-{\alpha }_{u}){Q}_{t-1}({A}_{j})+{U}_{u}({r}_{t-1}),$$ (40)
$$ {q} _ {t}({a} _ {j})=(1 - {\ alpha} _ {u}){q} _ {t-t-t-1}({a} _ {a} _ {j} _ {j})
where 1 − α u is the decay rate for unchosen actions. We additionally fit a reduced model of this strategy where β c = α c and β u = α u (similarly inspired by the RNN’s solution).
其中1 -αU是未选择作用的衰减率。我们还拟合了该策略的简化模型,其中βc =αC和βu =αU(同样受到RNN溶液的启发)。
The action probabilities for these models are generated via \({\rm{softmax}}\,({\{\beta ({Q}_{t}({A}_{i})+{X}_{t}({A}_{i}))\}}_{i})\) (X t = 0 for models without action perseverations). Both the action values and action perseverations are dynamical variables.
这些模型的动作概率是通过\({\ rm {softmax}}} \,({{\ {\ beta({q} _ {t}({a} _} _ {a} _ {i} _ {i})对于没有动作持久性的模型,t = 0。动作值和动作毅力都是动态变量。
Models for the original two-stage task
原始两阶段任务的模型
Model-free strategy (d = 3)
无模型策略(d = 3)
This model hypothesizes that the action values for each task state (first-stage state S 0 , second-stage states S 1 and S 2 ) are fully anti-correlated (\({Q}_{t}^{{S}_{0}}({A}_{1})=-{Q}_{t}^{{S}_{0}}({A}_{2})\), \({Q}_{t}^{{S}_{1}}({B}_{1})=-{Q}_{t}^{{S}_{1}}({B}_{2})\), \({Q}_{t}^{{S}_{2}}({B}_{3})=-{Q}_{t}^{{S}_{2}}({B}_{3})\)).
该模型假设每个任务状态的动作值(第一阶段s 0,第二阶段状态S 1和s 2)是完全反相关的(\({Q} _ {t}^{{s} _ {0}}}({a} _ {1})= - {q}\({Q} _ {t}^{{s} _ {1}}}({b} _ {1})= - {q} _ {Q} _ {t}^{s} {s} {s} _ {1}}}\({Q} _ {t}^{{s} _ {2}}}({b} _ {3})= - {q} _ {t} _ {t}^{s} {s} _ {s} _ {2}}}}}}}({b} _ {b} _ {3} _ {3} _ {3})\)\))。
The action values at the chosen second-stage state (for example, assuming B 1 or B 2 at S 1 is chosen) are updated by:
所选第二阶段状态的操作值(例如,选择S 1处的B 1或B 2)由以下更新:
$$\begin{array}{l}{Q}_{t}^{{S}_{1}}({a}_{t-1}^{{S}_{1}})={Q}_{t-1}^{{S}_{1}}({a}_{t-1}^{{S}_{1}})+{\alpha }_{2}({r}_{t-1}-{Q}_{t-1}^{{S}_{1}}({a}_{t-1}^{{S}_{1}}))\\ {Q}_{t}^{{S}_{1}}({\overline{{a}}}_{t-1}^{{S}_{1}})={Q}_{t-1}^{{S}_{1}}({\overline{{a}}}_{t-1}^{{S}_{1}})-{\alpha }_{2}({r}_{t-1}+{Q}_{t-1}^{{S}_{1}}({\overline{{a}}}_{t-1}^{{S}_{1}})),\end{array}$$ (41)
$$ \ begin {array} {l} {q} _ {t}^{{s} _ {1}}}}({a} _ {a} _ {t-1}^{1}})= {q} _ {t-1}^{{s} _ {1}}}}({a} _ {t-1}^{s} {s} {s} _ {1}}}})+{\ alpha} _ {2}({r} _ {t-1} - {q} _ {t-1}}^{{s} _ {1}}}({a} _ {a} _ {t-1}^{{q} _ {t}^{{s} _ {1}}}({\ overline {{a}}}} _ {t-1}^{s} {s} _ {1}} _ {1}}} = {q} _} _{t-1}^{{s} _ {1}}}({\ overline {{a}}} _ {t-1}^{{s} {s} _ {1}}}) - {\ alpha} _ {2}({r} _ {t-1}+{q} _ {t-1}^{{s} _ {1}}}}({\ overline {{a} {a}}}}} _ {
where \({\overline{{a}}}_{t-1}^{{S}_{1}}\) is the unchosen second-stage action at the chosen second-stage state, and α 2 is the learning rate for the second-stage states (0 ≤ α 2 ≤ 1). The second-stage action probabilities are generated via softmax \(({\beta }_{2}{Q}_{t}^{{S}_{1}}({B}_{1}),{\beta }_{2}{Q}_{t}^{{S}_{1}}({B}_{2}))\).
其中\ \({\ overline {{a}}} _ {t-1}^{{{s} _ {1}} \)是所选的第二阶段状态下未选择的第二阶段动作,而α2是第二阶段状态的学习率(0≤α2≤1d≤1)。第二阶段的动作概率是通过softmax \((({{\ beta} _ {2} {q} {q} _ {t}^{{s} {s} _ {1}}}({b} _ {1} _ {1}),{\ beta {\ beta} _ {2} {q} _ {t}^{{s} _ {1}}}}({b} _ {2}))\)\)。
The action values at the first-stage state (A 1 or A 2 at S 0 ) are updated by:
在第一阶段状态(s 0处的a或2)处的操作值由以下更新:
$$\begin{array}{c}{Q}_{t}^{{S}_{0},{\rm{m}}{\rm{f}}}({a}_{t-1}^{{S}_{0}})={Q}_{t-1}^{{S}_{0},{\rm{m}}{\rm{f}}}({a}_{t-1}^{{S}_{0}})+{\alpha }_{1}(\lambda {r}_{t-1}+(1-\lambda ){Q}_{t}^{{S}_{1}}({a}_{t-1}^{{S}_{1}})\\ \,\,\,\,\,\,-\,{Q}_{t-1}^{{S}_{0},{\rm{m}}{\rm{f}}}({a}_{t-1}^{{S}_{0}}))\\ {Q}_{t}^{{S}_{0},{\rm{m}}{\rm{f}}}({\overline{{a}}}_{t-1}^{{S}_{0}})={Q}_{t-1}^{{S}_{0},{\rm{m}}{\rm{f}}}({\overline{{a}}}_{t-1}^{{S}_{0}})-{\alpha }_{1}(\lambda {r}_{t-1}+(1-\lambda ){Q}_{t}^{{S}_{1}}({a}_{t-1}^{{S}_{1}})\\ \,\,\,\,\,\,+\,{Q}_{t-1}^{{S}_{0},{\rm{m}}{\rm{f}}}({\overline{{a}}}_{t-1}^{{S}_{0}})),\end{array}$$ (42)
$ \ begin {array} {c} {q} _ {t}^{{s} _ {0},{\ rm {m {m}} {\ rm {\ rm {f}}}}}}}}}}}}}}}}0}})= {q} _ {t-1}^{{{s} _ {0},{\ rm {m}}} {\ rm {f}}}}}}}}}({a} _} _ {a} _ {t-1}}} _ {1}(\ lambda {r} _ {t-1}+(1- \ lambda){Q} _ {\,\,\,\,\,\, - \, - {Q} _ {t-1}^{{s} _ {0},{\ rm {m {m}} {\ rm {f}}}}}}}}({q} _ {t}^{{s} _ {0},{\ rm {m}}} {\ rm {f}}}}}}}}}({\ overline {{a}}}}}} _ {t-1}}{t-1}^{{{s} _ {0},{\ rm {m}} {\ rm {f}}}}}}}}}}}({\ overline {{a}}}}} _ {t-1} _ {t-1}^}^{{s} {{s} _ {0} _ {0} _ {0}} _ {0}}} - {\ alpha} _ {1}(\ lambda {r} _ {t-1}+(1- \ lambda){Q} _ {\,\,\,\,\,\,\,\,{q} _ {t-1}^{{s} _ {0},{\ rm {m {m}} {\ rm {\ rm {f}}}}({\ overline {{a}}} _ {t-1}^{{s} _ {0}})),\ end {array} $$(42)
where \({\overline{{a}}}_{t-1}^{{S}_{0}}\) is the unchosen first-stage action, α 1 is the learning rate for the first-stage state (0≤ α 1 ≤1), and λ specifies the TD(λ) learning rule. The first-stage action probabilities are generated via softmax \(({\beta }_{1}{Q}_{t}^{{S}_{0},{\rm{m}}{\rm{f}}}({A}_{1}),{\beta }_{1}{Q}_{t}^{{S}_{0},{\rm{m}}{\rm{f}}}({A}_{2}))\).
其中\({\ overline {{a}}} _ {t-1}^{{{s} _ {0}} \)是未选择的第一阶段动作,α1是第一阶段状态的学习率(0≤α1≤1),并且λ表明TD(λ)学习规则。第一阶段的操作概率是通过softmax \(((({\ beta} _ {1} {q} {q} _ {t}^{{s} {s} _ {0},{\ rm {m {m {m {m {m {\ rm {\ rm {\ rm {f}}}}}}(} _ {1} {q} _ {t}^{{s} _ {0},{\ rm {M}}} {\ rm {f}}}}}}}}}}}}}}({a} _} _ {2} _ {2} _ {2}))\)\)\)。
Here \({Q}_{t}^{{S}_{0},{\rm{m}}{\rm{f}}}({A}_{1})\), \({Q}_{t}^{{S}_{1}}({B}_{1})\), and \({Q}_{t}^{{S}_{2}}({C}_{1})\) are the dynamical variables.
这里\({q} _ {t}^{{s} _ {0},{\ rm {m {m}}} {\ rm {f}}}}}}}}}}}({a} _ {1})\),\),\({q} _ {t}^{{s} _ {1}}({b} _ {1})\)和\({q} _ {t}^{t}^{{s} {s} _ {s} _ {2}}}}({2}}}(c}}(c} _ {c} _ {1} _ {1} _}
Model-based strategy (d = 2)
基于模型的策略(d = 2)
The update of action values at the chosen second-stage state is the same as the model-free strategy. The action values at the first-stage state (A 1 or A 2 at S 0 ) are determined by:
所选第二阶段状态下的动作值的更新与无模型策略相同。第一阶段状态(s 0处的1或2)处的动作值由:
$${Q}_{t}^{{S}_{0},{\rm{m}}{\rm{b}}}({A}_{i})=Pr[{S}_{1}|{A}_{i}]\mathop{\text{max}}\limits_{{B}_{j}}\,{Q}_{t}^{{S}_{1}}({B}_{j})+Pr[{S}_{2}|{A}_{i}]\mathop{\text{max}}\limits_{{C}_{j}}\,{Q}_{t}^{{S}_{2}}({C}_{j}).$$ (43)
$$ {q} _ {t}^{{s} _ {0},{\ rm {m}}} {\ rm {b}}}}}}}}}({a} _} _ {i}1} | {a} _ {i}] \ mathop {\ text {max}}} \ limits _ {{b} _ {j}}} \,{q} _ {t}^{{{s} _ {1}}({b} _ {j})+pr [{s} _ {2} | {a} _ {a} _ {i}] \ mathop {\ text{max}} \ limits _ {{c} _ {j}} \,{q} _ {t}^{t}^{{s} _ {2}}}}({c} _ {c} _ {j})。$$(43)
The first-stage action probabilities are generated via \({\rm{s}}{\rm{o}}{\rm{f}}{\rm{t}}{\rm{m}}{\rm{a}}{\rm{x}}\,({\beta }_{1}{Q}_{t}^{{S}_{0},{\rm{m}}{\rm{b}}}({A}_{1}),{\beta }_{1}{Q}_{t}^{{S}_{0},{\rm{m}}{\rm{b}}}({A}_{2}))\).
第一阶段的操作概率是通过\({\ rm {s}} {\ rm {O}} {\ rm {\ rm {f}} {\ rm {\ rm {t}} {\ rm {t}} {\ rm {m {m {m}}}} {} _ {1} {q} _ {t}^{{s} _ {0},{\ rm {M}}} {\ rm {b}}}}}}}}}}}}}}}({a} _ {1} _ {1}),{\ beta} _ {1} {q} _ {t}^{{s} _ {0},{\ rm {m}}} {\ rm {b}}}}}}}}}}}}}}({a} _} _ {2} _ {2} _ {2}))\)\)\)。
Only \({Q}_{t}^{{S}_{1}}({B}_{1})\) and \({Q}_{t}^{{S}_{2}}({C}_{1})\) are the dynamical variables.
仅\({q} _ {t}^{{s} _ {1}}({b} _ {1})\)\)和\({q} _ {t} _ {t}^{{s} {s} _ {2}}}}}}}(c}}(c} {c} _ {c} _ {c} _ {1} _}
Model-based mixture strategy (d = 3)
基于模型的混合物策略(d = 3)
This model considers the mixture of model-free and model-based strategies for the first-stage states. The net action values are determined by:
该模型考虑了第一阶段状态的无模型和基于模型的策略的混合。净动作值由:
$${Q}_{t}^{{S}_{0},{\rm{n}}{\rm{e}}{\rm{t}}}({A}_{i})=(1-w){Q}_{t}^{{S}_{0},{\rm{m}}{\rm{f}}}({A}_{i})+w{Q}_{t}^{{S}_{0},{\rm{m}}{\rm{b}}}({A}_{i}),$$ (44)
$$ {q} _ {ts} _ {0},{\ rm {and}}} {\ rme}}} {\ rm {t}}}}}}}}}}({a} _ {a} _ {i})=(i})=(1-w)=(1-w){\ rm {m}} {\ rm {f}}}}}}}({a} _ {i})+w {q} _ {t} _ {t}^{{s} _ {0},{\ rm {m}}} {\ rm {b}}}}}}}({a} _ {i}),$$(44)
where w controls the strength of the model-based component. The first-stage action probabilities are generated via \(\text{softmax}\,({\beta }_{1}{Q}_{t}^{{S}_{0},{\rm{n}}{\rm{e}}{\rm{t}}}({A}_{1}),{\beta }_{1}{Q}_{t}^{{S}_{0},{\rm{n}}{\rm{e}}{\rm{t}}}({A}_{2}))\). \({Q}_{t}^{{S}_{0},{\rm{m}}{\rm{f}}}({A}_{1})\), \({Q}_{t}^{{S}_{1}}({B}_{1})\) and \({Q}_{t}^{{S}_{2}}({C}_{1})\) are the dynamical variables.
W控制基于模型的组件的强度。第一阶段的动作概率是通过\(\ text {softmax} \,({\ beta)生成的} _ {1} {q} _ {t}^{{{s} _ {0},{\ rm {n}} {\ rm {e}} {\ rm {e}} {\ rm {t}}}}}}}}}}}({a} _} _} _ {1} _ {1})} _ {1} {q} _ {t}^{{s} _ {0},{\ rm {n}}} {\ rm {e}} {\ rm {e}} {\ rm {t}}}}}}}}}}}(\({Q} _ {t}^{{s} _ {0},{\ rm {m}}} {\ rm {f}}}}}}}}}}(a} _ {1}),\({Q} _ {t}^{{s} _ {1}}({b} _ {1})\)和\({q} _ {t} _ {t}^{s {s} {s} _ {2} _ {2}}}(c}}(c} _ {c} _ {1} _ {1} _}
Model-free strategy (d = 6)
无模型策略(d = 6)
Compared to the model-free strategy (d = 3), only the chosen action values at S 0 , S 1 , and S 2 are updated. The unchosen values are unchanged. \({Q}_{t}^{{S}_{0},{\rm{m}}{\rm{f}}}({A}_{1})\), \({Q}_{t}^{{S}_{0},{\rm{m}}{\rm{f}}}({A}_{2})\), \({Q}_{t}^{{S}_{1}}({B}_{1})\), \({Q}_{t}^{{S}_{1}}({B}_{2})\), \({Q}_{t}^{{S}_{2}}({C}_{1})\) and \({Q}_{t}^{{S}_{2}}({C}_{2})\) are the dynamical variables.
与无模型策略(d = 3)相比,仅更新S 0,S 1和S 2时所选的动作值。未选择的值没有变化。\({Q} _ {t}^{{s} _ {0},{\ rm {m}}} {\ rm {f}}}}}}}}}}(a} _ {1}),\({Q} _ {t}^{{s} _ {0},{\ rm {m}}} {\ rm {f}}}}}}}}}}(a} _ {2})\),\),\({Q} _ {t}^{{{s} _ {1}}}({b} _ {1})\),\({q} _ {t} _ {t}^{s} {s} {s} _ {1}}}\({Q} _ {t}^{{s} _ {2}}({C} _ {1})\)和\({q} _ {t} _ {t}^{s {s} {s} _ {s} _ {2}}}}}(c}}(c} _} _ {2} _ {2} _ {2}}
Model-based strategy (d = 4)
基于模型的策略(d = 4)
Compared to the model-based strategy (d = 2), only the chosen action values at S 1 , and S 2 are updated. The unchosen values are unchanged. \({Q}_{t}^{{S}_{1}}({B}_{1})\), \({Q}_{t}^{{S}_{1}}({B}_{2})\), \({Q}_{t}^{{S}_{2}}({C}_{1})\) and \({Q}_{t}^{{S}_{2}}({C}_{2})\) are the dynamical variables.
与基于模型的策略(d = 2)相比,仅在s 1和s 2处选择的动作值。未选择的值没有变化。\({Q} _ {t}^{{{s} _ {1}}}({b} _ {1})\),\({q} _ {t} _ {t}^{s} {s} {s} _ {1}}}\({Q} _ {t}^{{s} _ {2}}({C} _ {1})\)和\({q} _ {t} _ {t}^{s {s} {s} _ {s} _ {2}}}}}(c}}(c} _} _ {2} _ {2} _ {2}}
Model-based mixture strategy (d = 6)
基于模型的混合策略(d = 6)
Compared to the model-based mixture strategy (d = 3), only the chosen action values at S 0 , S 1 and S 2 are updated. The unchosen values are unchanged. \({Q}_{t}^{{S}_{0},{\rm{m}}{\rm{f}}}({A}_{1})\), \({Q}_{t}^{{S}_{0},{\rm{m}}{\rm{f}}}({A}_{2})\), \({Q}_{t}^{{S}_{1}}({B}_{1})\), \({Q}_{t}^{{S}_{1}}({B}_{2})\), \({Q}_{t}^{{S}_{2}}({C}_{1})\) and \({Q}_{t}^{{S}_{2}}({C}_{2})\) are the dynamical variables.
与基于模型的混合物策略(d = 3)相比,仅更新S 0,S 1和S 2时所选的动作值。未选择的值没有变化。\({Q} _ {t}^{{s} _ {0},{\ rm {m}}} {\ rm {f}}}}}}}}}}(a} _ {1}),\({Q} _ {t}^{{s} _ {0},{\ rm {m}}} {\ rm {f}}}}}}}}}}(a} _ {2})\),\),\({Q} _ {t}^{{{s} _ {1}}}({b} _ {1})\),\({q} _ {t} _ {t}^{s} {s} {s} _ {1}}}\({Q} _ {t}^{{s} _ {2}}({C} _ {1})\)和\({q} _ {t} _ {t}^{s {s} {s} _ {s} _ {2}}}}}(c}}(c} _} _ {2} _ {2} _ {2}}
Model-free strategy with reward utility (d = 3)
带有奖励实用程序的无模型策略(d = 3)
This model is constructed from the RNN’s strategy. Similar to the model-free strategy (d = 3), it hypothesizes that the action values for each task state (first-stage state S 0 , second-stage states S 1 and S 2 ) are fully anti-correlated (\({Q}_{t}^{{S}_{0}}({A}_{1})=-{Q}_{t}^{{S}_{0}}({A}_{2})\), \({Q}_{t}^{{S}_{1}}({B}_{1})=-{Q}_{t}^{{S}_{1}}({B}_{2})\), \({Q}_{t}^{{S}_{2}}({B}_{3})=-{Q}_{t}^{{S}_{2}}({B}_{3})\)).
该模型是根据RNN的策略构建的。与无模型策略(d = 3)相似,它假设每个任务状态的动作值(第一阶段s 0,第二阶段状态s 1和s 2)是完全反相关的(\({Q} _ {t}^{{s} _ {0}}}({a} _ {1})= - {q}\({Q} _ {t}^{{s} _ {1}}}({b} _ {1})= - {q} _ {Q} _ {t}^{s} {s} {s} _ {1}}}\({Q} _ {t}^{{s} _ {2}}}({b} _ {3})= - {q} _ {t} _ {t}^{s} {s} _ {s} _ {2}}}}}}}({b} _ {b} _ {3} _ {3} _ {3})\)\))。
It assumes that when receiving one reward, the reward utility (that is, equivalently, the preference setpoint) for the chosen action at the first-stage state S 0 is \({U}^{{S}_{0}}(1)=1\), for the chosen action at the chosen second-stage state S 1 (or S 2 ) is \({U}^{{S}_{1}}(1)=1\), and for the (motor-level) chosen action at the unchosen second-stage state S 2 (or S 1 ) is \({U}^{{S}_{2}}(1)={U}_{{\rm{other}}}\) (for example, B 1 at the chosen S 1 and C 1 at unchosen S 2 are the same motor-level action). When receiving no reward, the reward utility for the chosen action at the first-stage state S 0 is \({U}^{{S}_{0}}(0)={U}_{1{\rm{st}},{\rm{zero}}}\), for the chosen action at the chosen second-stage state (assuming S 1 ) is \({U}^{{S}_{1}}(0)={U}_{2{\rm{nd}},{\rm{zero}}}\), and for the (motor-level) chosen action at the unchosen second-stage state (assuming S 2 ) is \({U}^{{S}_{2}}(0)=-{U}_{{\rm{other}}}\). The chosen action values at the chosen second-stage state (for example, assuming B 1 or B 2 at S 1 ) are updated by:
它假设在收到一个奖励时,在第一个阶段状态S 0处选择的动作的奖励实用程序(即优先设定点)是\({u}^{{s} {s} _ {0}} _ {0}}}(1)= 1 \)\({U}^{{s} _ {1}}(1)= 1 \),对于未选择的第二阶段状态S 2(或S 1)的(电动机级)的操作是\({u}^{{s} _ {2}}(1)= {u} _ {{{\ rm {其他}}}} \)(例如,所选的S 1和c 1处的b 1 at n n ot Chosen at nOtchose s 2是相同的电动机级别的动作)。当不收到奖励时,在第一阶段s 0处所选操作的奖励实用性为\({u}^{{s} _ {0}}}}}(0)= {u} _ {\ rm {st}}\({\({u}^{{s} _ {2}}}(0)= - {u} _ {{\ rm {其他}}} \)。选定的第二阶段状态的选定操作值(例如,假设在S 1处的B 1或B 2)被更新:
$${Q}_{t}^{{S}_{1}}({a}_{t-1}^{{S}_{1}})={Q}_{t-1}^{{S}_{1}}({a}_{t-1}^{{S}_{1}})+{\alpha }_{2}({U}^{{S}_{1}}({r}_{t-1})-{Q}_{t-1}^{{S}_{1}}({a}_{t-1}^{{S}_{1}})),$$ (45)
$$ {q} _ {t}^{{s} _ {1}}}}({a} _ {t-1}^{{s} {s} _ {1}})= {q})= {q}_ {t-1}^{{s} _ {1}}}({a} _ {t-1}^{{s} _ {1}}})+{\ alpha} _ {2}({u}^{{s} _ {1}}}({r} _ {t-1}) - {q} _ {t-1}^{s} {s} {s} _ {1}}}}(}
where α 2 is the learning rate for the second-stage states (0 ≤ α 2 ≤ 1). The (motor-level) chosen action values (that is, \({\widetilde{a}}_{t-1}^{{S}_{2}}={C}_{1}\) if \({a}_{t-1}^{{S}_{1}}={B}_{1}\) and, \({\widetilde{a}}_{t-1}^{{S}_{2}}={C}_{2}\) if \({a}_{t-1}^{{S}_{1}}={B}_{2}\)) at the unchosen second-stage state (for example, assuming C 1 or C 2 at S 2 ) are updated by:
其中α2是第二阶段状态的学习率(0≤α2≤1)。(电机级)选择的操作值(即,\({\ widetilde {a}} _ {t-1}}^{{s} _ {2}} = {c} _ {c} _ {1} _ {1}}\({a} _ {t-1}^{{{s} _ {1}} = {b} _ {1} \)和,\({\ widetilde {A}}}} _ {t-1} _ {t-1}}\ \({a} _ {t-1}^{{s} _ {1}} = {b} _ {2} \)在未选择的第二阶段状态(例如,假设在s 2处的C 1或C 2)是:以下更新
$${Q}_{t}^{{S}_{2}}({\widetilde{a}}_{t-1}^{{S}_{2}})={Q}_{t-1}^{{S}_{2}}({\widetilde{a}}_{t-1}^{{S}_{2}})+{\alpha }_{2}({U}^{{S}_{2}}({r}_{t-1})-{Q}_{t-1}^{{S}_{2}}({\widetilde{a}}_{t-1}^{{S}_{2}})).$$ (46)
$$ {q} _ {t}^{{s} _ {2}}}}({\ widetilde {a}} _ {t-1}^{t-1}^{{s} _ {s} _ {2}}} = {q})= {q}_ {t-1}^{{s} _ {2}}}({\ widetilde {a}} _ {t-1}^{{s} {s} _ {2}}}})+{\ alpha} _ {2}({u}^{{s} _ {2}}}}({r} _ {t-1}) - {q} _ {q} _ {t-1}^{{{{s} _ {2}}({\ widetilde {a}} _ {t-1}^{{s} _ {2}}))。$$(46)
The second-stage action probabilities are generated via \(\text{softmax}\,({\beta }_{2}{Q}_{t}^{{S}_{1}}({B}_{1}),{\beta }_{2}{Q}_{t}^{{S}_{1}}({B}_{2}))\).
第二阶段的动作概率是通过\(\ text {softmax} \,({{\ beta} _ {2} {q} {q} _ {t}^{t}^{{s} _ {s} _ {1}}}}}}}}}}}({b}}({b} _ {1} _ {1}),{} _ {2} {q} _ {t}^{{s} _ {1}}}}({b} _ {2}))\)\)。
The action values at the first-stage state (A 1 or A 2 at S 0 ) are updated by:
在第一阶段状态(s 0处的a或2)处的操作值由以下更新:
$${Q}_{t}^{{S}_{0}}({a}_{t-1}^{{S}_{0}})={Q}_{t-1}^{{S}_{0}}({a}_{t-1}^{{S}_{0}})+{\alpha }_{1}({U}^{{S}_{0}}({r}_{t-1})-{Q}_{t-1}^{{S}_{0}}({a}_{t-1}^{{S}_{0}}))$$ (47)
$$ {q} _ {t}^{{s} _ {0}}}({a} _ {t-1}^{{s} {s} _ {0}})= {q})= {q}_ {t-1}^{{s} _ {0}}}}({a} _ {t-1}^{{s} {s} _ {0}}})+{\ alpha} _ {1}({u}^{{s} _ {0}}}({r} _ {t-1}) - {q} _ {t-1}^{t-1}^{{s} {s} _ {0} _ {0}}(0}}}(
where α 1 is the learning rate for the first-stage state (0 ≤ α 1 ≤ 1). The first-stage action probabilities are generated via \(\text{softmax}\,({\beta }_{1}{Q}_{t}^{{S}_{0}}({A}_{1}),{\beta }_{1}{Q}_{t}^{{S}_{0}}({A}_{2}))\).
其中α1是第一阶段状态的学习率(0≤α1≤1)。第一阶段的动作概率是通过\(\ text {softmax} \,({{\ beta} _ {1} {q} {q} _ {t}^{s} {s} _ {0}}} _ {0}}({a} _} _} _ {1} _ {1}),{} _ {1} {q} _ {t}^{{s} _ {0}}}({a} _ {2}))\)\)。
Here \({Q}_{t}^{{S}_{0}}({A}_{1})\), \({Q}_{t}^{{S}_{1}}({B}_{1})\), and \({Q}_{t}^{{S}_{2}}({C}_{1})\) are the dynamical variables.
这里\({Q} _ {t}^{{s} _ {0}}}({a} _ {1})\),\({q} _ {t} _ {t}^{s} {s} {s} _ {1}}}}}}(b}}(b} _}\({q} _ {t}^{{s} _ {2}}}({c} _ {1})\)是动态变量。
Model fitting
模型拟合
Maximum likelihood estimation
最大似然估计
The parameters in all models were optimized on the training dataset to maximize the log-likelihood (that is, minimize the negative log-likelihood, or cross-entropy) for the next-action prediction. The loss function is defined as follows:
所有模型中的参数均在训练数据集上进行了优化,以最大程度地提高对数可能性(即最小化负模样或跨渗透率),以实现下一个动作预测。损失函数定义如下:
$$\begin{array}{l}{\mathcal{L}}\,=\,-\log \Pr [\text{action sequences from one subject given}\\ \,\,\text{one model}]\\ \,=\,-\mathop{\sum }\limits_{n=1}^{{N}_{{\rm{session}}}}\mathop{\sum }\limits_{t=1}^{{T}_{n}}\log \Pr [\text{observing}\,{a}_{t}\,\text{given past}\\ \,\,\text{observations and the model}],\end{array}$$ (48)
$ \ begin {array} {l} {\ Mathcal {l}}} \,= \, - \ log \ pr \ pr [\ text {action {action {action segences from一个主题给定} \ \ \ \ \,\,\,\ text {一个模型}]} \ limits_ {n = 1}^{{n} _ {{\ rm {session}}}}}}} \ Mathop {\ sum} \ limits_ {t = 1}^{{t} {[\ text {observing} \,{a} _ {t} \,\ text {给定} \ \ \ \ \,\,\,\ text {observations and the Model}],\ end end {array} $} $ 4(48)
where N session is the number of sessions and T n is the number of trials in session n.
其中n会话是会话的数量,而t n是n会议中的试验数。
Nested cross-validation
嵌套交叉验证
To avoid overfitting and ensure a fair comparison between models with varying numbers of parameters, we implemented nested cross-validation. For each animal, we first divided sessions into non-overlapping shorter blocks (approximately 150 trials per block) and allocated these blocks into ten folds. In the outer loop, nine folds were designated for training and validation, while the remaining fold was reserved for testing. In the inner loop, eight of the nine folds were assigned for training (optimizing a model’s parameters for a given set of hyperparameters), and the remaining fold of the nine was allocated for validation (selecting the best-performing model across all hyperparameter sets). Notice that this procedure allows different hyperparameters for each test set.
为了避免过度拟合,并确保具有不同参数数量的模型之间进行公平比较,我们实现了嵌套的交叉验证。对于每种动物,我们首先将会话分为非重叠的较短块(每块大约150个试验),并将这些块分配为十倍。在外循环中,指定了九个折叠以进行训练和验证,而剩余的折叠则保留用于测试。在内部循环中,分配了九个倍数中的八个用于训练(优化了给定的一组超参数的模型参数),并分配了九个折叠量的剩余折叠以进行验证(在所有超参数组中选择最佳的模型)。请注意,此过程允许每个测试集的不同超参数。
RNNs’ hyperparameters encompassed the L1-regularization coefficient on recurrent weights (drawn from 10−5, 10−4, 10−3, 10−2 or 10−1, depending on the experiments), the number of training epochs (that is, early stopping), and the random seed (three seeds). For cognitive models, the only hyperparameter was the random seed (used for parameter initialization). The inner loop produced nine models, with the best-performing model, based on average performance in the training and validation datasets, being selected and evaluated on the unseen testing fold. The final testing performance was computed as the average across all ten testing folds, weighted by the number of trials per block. This approach ensures that test data is exclusively used for evaluation and is never encountered during training or selection.
RNNS的超参数包括在复发重量上的L1型规范系数(取决于10-5、10-4、10-3、10-2或10-1,取决于实验),训练时期的数量(即,早期停止)和随机种子(三种种子)。对于认知模型,唯一的高参数是随机种子(用于参数初始化)。内部循环基于训练和验证数据集的平均性能,制作了九个模型,并在看不见的测试折叠中选择和评估。最终的测试性能计算为所有十个测试折叠的平均值,并由每个块试验数量加权。这种方法可确保测试数据专门用于评估,并且在培训或选择过程中永远不会遇到。
During RNN training, we employed early stopping if the validation performance failed to improve after 200 training epochs. This method effectively prevents RNN overfitting on the training data. According to this criterion, a more flexible model may demonstrate worse performance than a less flexible one, as the training for the former could be halted early due to insufficient training data. However, it is expected that the more flexible model would continue to improve with additional training data (for example, see Supplementary Fig. 8).
在RNN培训期间,如果验证性能在200个训练时期未能改善,我们就采用了尽早停止。此方法有效地防止了RNN过度拟合培训数据。根据该标准,更灵活的模型可能表现出比灵活的模型更差,因为由于训练数据不足,对前者的训练可能会早日停止。但是,预计更灵活的模型将通过其他培训数据继续改善(例如,请参见图8补充)。
We note that, in the rich-data situation, this training–validation–test split in (nested) cross-validation is better than the typical usage of AIC62, corrected AIC (AICc)63 or BIC64 in cognitive modelling, due to the following reasons65: the (nested) cross-validation provides a direct and unbiased estimate of the expected extra-sample test error, which reflects the generalization performance on new data points with inputs not necessarily appearing in the training dataset; by contrast, AIC, AICc and BIC can only provide asymptotically unbiased estimates of in-sample test error under some conditions (for example, models are linear in their parameters), measuring the generalization performance on new data points with inputs always appearing in the training dataset (the labels could be different from those in the training dataset due to noise). Furthermore, in contrast to regular statistical models, neural networks are singular statistical models with degenerate Fisher information matrices. Consequently, estimating the model complexity (the number of effective parameters, as used in AIC, AICc or BIC) in neural networks requires estimating the real log canonical threshold66, which falls outside the scope of this study.
We note that, in the rich-data situation, this training–validation–test split in (nested) cross-validation is better than the typical usage of AIC62, corrected AIC (AICc)63 or BIC64 in cognitive modelling, due to the following reasons65: the (nested) cross-validation provides a direct and unbiased estimate of the expected extra-sample test error, which reflects the generalization performance on new data培训数据集中不一定会出现输入的点;相比之下,AIC,AICC和BIC只能在某些条件下(例如,模型在其参数中是线性的),对样本内测试误差的渐近估计值,测量在训练数据集中始终出现的新数据点上的概括性能(由于噪声而导致训练数据集中的标签可能与训练数据集中的标签不同)。此外,与常规的统计模型相比,神经网络是具有归化Fisher Information矩阵的单数统计模型。因此,估计神经网络中AIC,AICC或BIC中使用的有效参数的数量(有效参数的数量)需要估计实际的对数规范阈值66,该阈值超出了这项研究的范围。
Estimating the dimensionality of behaviour
估计行为的维度
For each animal, we observed that the predictive performance of RNN models initially improves and then saturates, or sometimes declines as the number d of dynamical variables increases. To operationally estimate the dimensionality d * of behaviour, we implemented a statistical procedure that satisfies two criteria: (1) the RNN model with d * dynamical variables significantly outperforms all RNN models with d < d * dynamical variables (using a significance level of 0.05 in the t-tests of predictive performance conducted over outer folds); (2) any RNN model with \({d}^{{\prime} }\) (\({d}^{{\prime} } > {d}_{* }\)) dynamical variables does not exhibit significant improvement over all RNN models with \(d < {d}^{{\prime} }\) dynamical variables.
对于每种动物,我们观察到RNN模型的预测性能最初会改善并饱和,或者有时随着动态变量的数量增加而下降。为了估计行为的维度D *,我们实施了一个满足两个标准的统计过程:(1)具有D *动力学变量的RNN模型显着胜过所有具有D
Our primary objective is to estimate the intrinsic dimensionality (reflecting the latent variables in the data-generating process), not the embedding dimensionality67. However, it is important to consider the practical limitations associated with the estimation procedure. For instance, RNN models may fail to uncover certain latent variables due to factors such as limited training data or variables operating over very long time scales, leading to an underestimation of d * . Additionally, even if all d * latent variables are accurately captured, the RNN models may still require d ≥ d * dynamical variables to effectively and losslessly embed d * -dimensional dynamics, particularly if they exhibit high nonlinearity, potentially resulting in an overestimation of d * . A comprehensive understanding of these factors is crucial for future studies.
我们的主要目标是估计固有维度(反映数据生成过程中的潜在变量),而不是嵌入维度67。但是,重要的是要考虑与估计程序相关的实际限制。例如,由于诸如训练数据有限或在很长的时间尺度上运行的变量之类的因素,RNN模型可能无法发现某些潜在变量,从而低估了D *。此外,即使所有d *潜在变量都被准确捕获,RNN模型仍然可能需要D≥D *动态变量才能有效,无损耗的D *维动力学,特别是如果它们表现出较高的非线性,可能会导致D *的高估。对这些因素的全面理解对于未来的研究至关重要。
Knowledge distillation
知识蒸馏
We employ the knowledge distillation framework33 to fit models to individual subjects, while simultaneously leveraging group data: first fitting a teacher network to data from multiple subjects, and then fitting a student network to the outputs of the teacher network corresponding to an individual subject.
我们采用知识蒸馏框架33将模型适合单个主题,同时利用组数据:首先将教师网络拟合到来自多个主题的数据,然后将学生网络拟合到与单个主题相对应的教师网络的输出。
Teacher network
教师网络
In the teacher network (TN), each subject is represented by a one-hot vector. This vector projects through a fully connected linear layer into a subject-embedding vector e sub , which is provided as an additional input to the RNN. The teacher network uses 20 units in its hidden layer and uses the same output layer and loss (cross-entropy between the next-trial action and the predicted next-trial action probability) as in previous RNN models.
在教师网络(TN)中,每个主题均由一个速率向量表示。该矢量通过完全连接的线性层投射到主题插入的向量E子,该载体是作为RNN的附加输入提供的。教师网络在其隐藏层中使用20个单元,并使用相同的输出层和损失(在下一步操作和预测的下一步动作概率之间进行了交叉渗透率)。
Student network
学生网络
The student network (SN) has the same architecture as previous tiny RNNs. The only difference is that, during training and validation, the loss is defined as cross-entropy between the next-trial action probability provided by the teacher and the next-trial action probability predicted by the student:
学生网络(SN)具有与以前的Tiny RNN相同的架构。唯一的区别是,在培训和验证期间,损失被定义为教师提供的下一项审判概率与学生预测的下一步审判概率之间的跨深思:
$$\begin{array}{l}{\mathcal{L}}=-\mathop{\sum }\limits_{n=1}^{{N}_{{\rm{session}}}}\mathop{\sum }\limits_{t=1}^{{T}_{n}}\mathop{\sum }\limits_{a=1}^{{N}_{a}}{\text{Pr}}^{{\rm{TN}}}[{a}_{t}=a| \,\text{past observations}]\\ \,\,\times \,\log {\text{Pr}}^{{\rm{SN}}}[{a}_{t}=a| \,\text{past observations}],\end{array}$$ (49)
$ \ begin {array} {l} {\ Mathcal {l}} = - \ Mathop {\ sum} \ limits_ {n = 1}^{{n} _ {{\ rm {\ rm {session}}}}}}}}}}} \ Mathop {} \ limits_ {t = 1}^{{t} _ {n}} \ Mathop {\ sum} \ limits_ {a = 1}^{{n} {n} _ {a}}}}}} {\,\ text {过去的观察}] \\ \,\,\ \ times \,\ log {\ text {pr}}}^{{\ rm {sn}}}}}}}}}}} [{a} _ {t} = a |\,\ text {过去的观察}],\ end {array} $$(49)
where N session is the number of sessions, T n is the number of trials in session n, and N a is the number of actions.
如果n会话是会话的数量,则t n是会话n中的试验数,而n a是动作数。
Training, validation and test data in knowledge distillation for the mouse in the Akam dataset
AKAM数据集中鼠标的知识蒸馏中的培训,验证和测试数据
To study the influence of the number of training trials from one representative mouse on the performance of knowledge distillation, we employed a procedure different from nested cross-validation. This procedure splits the data from animal M into two sets. The first set consisted of 25% of the trials and was used as a hold-out M-test dataset. The second set consisted of the remaining 75% trials, from which smaller datasets of different sizes were sampled. From each sampled dataset, 90% of the trials were used for training (M-training dataset) and 10% for validation (M-validation dataset). Next, we split the data from all other animals, with 90% of the data used for training (O-training dataset) and 10% for validation (O-validation dataset).
为了研究一只代表性小鼠的训练试验数量对知识蒸馏的性能的影响,我们采用了一种与嵌套交叉验证不同的程序。该过程将数据从动物M分为两组。第一组由25%的试验组成,并用作持有的M-Test数据集。第二组由剩余的75%试验组成,从中,采样了不同大小的较小数据集。从每个采样数据集中,使用了90%的试验进行培训(M-Training数据集),为验证(M-Validation数据集)10%。接下来,我们将数据从所有其他动物分开,其中90%用于培训(O-Training数据集)和10%用于验证(O-Validation数据集)。
After dividing the datasets as described above, we trained the models. The solo RNNs were trained to predict choices on the M-training dataset and selected on the M-validation dataset. The teacher RNNs were trained to predict choices on the M- and O-training datasets and selected on the M- and O-validation datasets. The number of embedding units in the teacher RNNs was selected based on the M-validation dataset. The student RNNs were trained on the M-training dataset and selected on the M-validation dataset, but with the training target of action probabilities provided by the teacher RNNs. Here the student RNNs and the corresponding teacher RNNs were trained on the same M-training dataset. Finally, all models were evaluated on the unseen M-test data.
如上所述将数据集划分后,我们训练了模型。对单个RNN进行了训练,可以预测M-Training数据集上的选择,并在M-Validation数据集上进行选择。培训了教师RNN,可以预测M-和O-Training数据集上的选择,并在M-和O-validation数据集中选择。根据M验证数据集选择了教师RNN中嵌入单元的数量。在M-Training数据集上对学生进行了培训,并在M验证数据集上选择,但随着教师RNN提供的动作概率的培训目标。在这里,学生和相应的老师RNN在同一M培训数据集上进行了培训。最后,所有模型均在看不见的M检验数据上评估。
When training the student RNNs, due to symmetry in the task, we augment the M-training datasets by flipping the action and second-stage states, resulting in an augmented dataset that is four times the size of the original one, similar to29. One key difference between our augmentation procedure and that of29 is that the authors augmented the data for training the group RNNs, where the potential action bias presented in the original dataset (and other related biases) becomes invisible to the RNNs. By contrast, our teacher RNNs are trained only on the original dataset, where any potential action biases can be learned. Even if we augment the training data later for the student networks, the biases learned by the teacher network can still be transferred into the student networks. In addition to direct augmentation, simulating the teacher network can be another method to generate pseudo-data. The benefit of these pseudo-data was discussed in model compression68.
在培训学生RNN时,由于任务中的对称性,我们通过翻转动作和第二阶段状态来增强M训练数据集,从而增加了一个增强数据集,该数据集是原始数据的四倍,类似于29。我们的增强程序和29 OF 29之间的一个关键区别是,作者增加了培训RNN的数据,其中原始数据集中存在的潜在动作偏差(以及其他相关偏见)对RNN不可见。相比之下,我们的老师RNN仅在原始数据集上进行培训,在该数据集中可以学习任何潜在的动作偏见。即使我们以后增加了学生网络的培训数据,教师网络所学的偏见仍然可以转移到学生网络中。除了直接增强外,模拟教师网络还可能是生成伪数据的另一种方法。这些伪数据的好处在模型压缩中讨论了68。
Protocols for training, validating and testing models in human datasets
人数据集中培训,验证和测试模型的协议
Interspersed split protocol
散布的拆分协议
In the three human datasets, each subject only performs one block of 100–200 trials. In the standard practice of cognitive modelling, the cognitive models are trained and tested on the same block, leading to potential overfitting and exaggerated performance. While it is possible to directly segment one block into three sequences for training, validation, and testing, this might introduce undesired distributional shifts in the sequences due to the learning effect. To ensure a fair comparison between RNNs and cognitive models, here we propose a new interspersed split protocol to define the training, validation and testing trials, similar to the usage of goldfish loss to prevent the memorization of training data in language models69. Specifically, we randomly sample without replacement ~75% trial indexes for training, ~12.5% trial indexes for validation and ~12.5% trial indexes for testing (three-armed reversal learning task: 120/20/20 (training/validation/testing); four-armed drifting bandit task: 110/20/20; original two-stage task: 150/25/25). We then feed in the whole block of trials as the model’s inputs, obtain the output probabilities for each trial, and calculate the training, validation, and testing losses for each set of trial indexes, separately. This protocol guarantees the identical distribution between three sets of trials.
在三个人类数据集中,每个受试者仅执行一个100-200个试验的块。在认知建模的标准实践中,认知模型在同一块上进行了训练和测试,从而导致潜在的过度拟合和夸张的性能。尽管可以将一个块直接分为三个序列进行训练,验证和测试,但由于学习效果,这可能会引入序列中不希望的分布变化。为了确保RNN和认知模型之间的公平比较,我们在这里提出了一个新的散布的拆分协议,以定义培训,验证和测试试验,类似于使用Goldfish损失的使用,以防止语言模型中训练数据的记忆69。Specifically, we randomly sample without replacement ~75% trial indexes for training, ~12.5% trial indexes for validation and ~12.5% trial indexes for testing (three-armed reversal learning task: 120/20/20 (training/validation/testing); four-armed drifting bandit task: 110/20/20; original two-stage task: 150/25/25).然后,我们将整个试验范围作为模型输入,获取每个试验的输出概率,并分别计算每组试验指数的培训,验证和测试损失。该协议保证了三组试验之间的相同分布。
One possible concern is whether the test data is leaked into the training data in this protocol. For instance, the models are trained on the input sequence ((a 1 , r 1 ), (a 2 , r 2 ), (a 3 , r 3 )) to predict a 4 and later tested on the input sequence ((a 1 , r 1 ), (a 2 , r 2 )) to predict a 3 . In this scenario, while the models see a 3 in the input during training, they never see a 3 in the output. Thus, models are not trained to learn the input–output mapping from ((a 1 , r 1 ), (a 2 , r 2 )) to a 3 , which is evaluated during testing. We confirmed that this procedure prevents data leakage on artificially generated choices (Supplementary Fig. 40).
一个可能的问题是,是否将测试数据泄漏到该协议中的培训数据中。例如,对模型进行了输入序列((A 1,r 1),(a 2,r 2),(a 3,r 3))的训练,以预测A 4及以后在输入序列(((A 1,r 1),(A 2,R 2))上测试以预测A 3。在这种情况下,虽然模型在训练期间的输入中看到了3个,但它们在输出中从未看到3个。因此,未经训练模型来学习从((a 1,r 1),(a 2,r 2))到3的输入输出映射,该映射在测试过程中进行了评估。我们确认此过程可防止人工产生的选择上的数据泄漏(补充图40)。
Cross-subject split protocol
交叉对象拆分协议
In addition to the interspersed split protocol, it is possible to train the RNNs on a proportion of subjects and evaluate them on held-out subjects (that is, zero-shot generalization), a cross-subject split protocol. To illustrate this protocol, we first divided all subjects into six folds of cross-validation. The teacher network was trained and validated using five folds and tested on the remaining one fold. For each subject in the test fold, because each subject only completed one task block, student networks are trained on the action-augmented blocks (to predict the teacher’s choice probabilities for the subject), validated on the original block (to predict the teacher’s choice probabilities for the subject), and tested on the original block (to predict actual choices of the subject). By design, both teacher networks and student networks will not overfit the subjects’ choices in the test data. The cognitive models were trained and validated using five folds and tested on the remaining one fold. We presented the results in Supplementary Fig. 41.
除了散布的拆分协议外,还可以按比例训练RNN,并在持有的受试者(即零弹性概括)上评估它们,这是一种交叉对象分配协议。为了说明此协议,我们首先将所有受试者分为六倍交叉验证。对教师网络进行了培训和验证,并在其余的一倍上进行了测试。对于测试折叠中的每个主题,由于每个受试者仅完成一个任务块,因此对学生网络进行了培训,请在动作启动的块上进行培训(以预测教师的选择概率),并在原始块上进行了验证(以预测教师的选择概率),并在原始块上进行了测试(以预测主题的实际选择)。根据设计,教师网络和学生网络都不会在测试数据中过度构成主题的选择。认知模型使用五倍训练和验证,并在其余一倍上进行了测试。我们在补充图41中介绍了结果。
Phase portraits
阶段肖像
Models with d = 1
D = 1的模型
Logit
logit
In each trial t, a model predicts the action probabilities Pr(a t = A 1 ) and Pr(a t = A 2 ). We define the logit L(t) (log odds) at trial t as \(L(t)=\log (\Pr ({a}_{t}={A}_{1})/\Pr ({a}_{t}={A}_{2}))\). When applied to probabilities computed via softmax, the logit yields \(L(t)=\log ({e}^{\beta {o}_{t}^{(1)}}/{e}^{\beta {o}_{t}^{(2)}})=\beta ({o}_{t}^{(1)}-{o}_{t}^{(2)})\), where \({o}_{t}^{(i)}\) is the model’s output for action a t = A i before softmax. Thus, the logit can be viewed as reflecting the preference for action A 1 over A 2 : in RNNs, the logit corresponds to the score difference \({o}_{t}^{(1)}-{o}_{t}^{(2)}\); in model-free and model-based RL models, the logit is proportional to the difference in first-stage action values Q t (A 1 ) − Q t (A 2 ); in Bayesian inference models, the logit is proportional to the difference in latent-state probabilities \({\Pr }_{t}(h=1)-{\Pr }_{t}(h=2)=2{\Pr }_{t}(h=1)-1\).
在每个试验t中,一个模型可以预测动作概率PR(a t = a 1)和pr(a t = a 2)。我们将试验t的logit l(t)(log grds)定义为\(l(t)= \ log(\ pr({{a} _ {t} = {a} = {a} _ {1})/\ pr({a} _ {a} _ {t} = {t} = {a} _} _ {2} _ {2}))当应用于通过SOFTMAX计算的概率时,logit会产生\(l(t)= \ log({e}^{\ beta {\ beta {o} _ {t}^{(1)}}}}/{e}}/{e}({o} _ {t}^{(1)} - {o} _ {t}^{(2)})\),其中\({o} _ {t}^{t}^{(i)} \)是动作a t = a i i i i t = a i i i i的模型。因此,可以将logit视为反映2:2:在rnns上的动作a 1的偏好,logit对应得分差\({o} _ {t} _ {t}^{(1)} - {O} _ {t} _ {在不含模型和基于模型的RL模型中,logit与第一阶段动作值q t(a 1)-q t(a 2)的差异成正比;在贝叶斯推理模型中,logit与潜在态概率的差异\({\ pr} _ {t}(h = 1) - {\ pr} _ {t}(h = 2)= 2 {\ pr} {\ pr} _ {t} _ {t}(h = 1) - \ \)。
Logit change
logit更改
We define the logit change, ΔL(t), in trial t as the difference between L(t + 1) and L(t). In one-dimensional models, ΔL(t) is a function of the input and L(t), forming a vector field.
我们将logit变化定义为试验t中的Δl(t),为L(t + 1)和L(t)之间的差异。在一维模型中,Δl(t)是输入和l(t)的函数,形成矢量场。
Stability of fixed points
固定点的稳定性
Here we derive the stability of a fixed point in one-dimensional discrete dynamical systems. The system’s dynamics update according to:
在这里,我们在一维离散动力系统中得出了固定点的稳定性。该系统的动态更新根据:
$${L}_{{\rm{next}}}={f}_{I}(L),$$ (50)
$$ {l} _ {{\ rm {next}}}} = {f} _ {i}(l),$$(50)
where L is the current-trial logit, L next is the next-trial logit, and f I is a function determined by input I (omitted for simplicity). At a fixed point, denoted by L = L*, we have
其中l是当前的审判logit,l下一个是下一个审判logit,而f i是由输入i确定的函数(为简单起见)。在用l = l*表示的固定点,我们有
$${L}^{* }=f({L}^{* }).$$ (51)
$$ {l}} {*} = f({l} {{*})。 $$(51)
Next, we consider a small perturbation δL around the fixed point:
接下来,我们考虑固定点附近的小扰动ΔL:
$$\begin{array}{l}{L}_{{\rm{next}}}\,=\,f({L}^{* }+\delta L)\\ \,\,\approx \,f({L}^{* })+{f}^{{\prime} }({L}^{* })\delta L\\ \,\,=\,{L}^{* }+{f}^{{\prime} }({L}^{* })\delta L.\end{array}$$ (52)
$ \ begin {array} {l} {l} _ {{{\ rm {next}}}}}} \,= \,f({l}^{*}+\ delta l)\ \ \ \ \ \ \ \ \ \ \ \ \,\,\,\,\,\,\,\,f(}({l}^{*})\ delta l \\ \ \ \ \,\,= \,{l}^{*}+{f}
The fixed point is stable only when \(-1 < {f}^{{\prime} }({L}^{* }) < 1\). Because the logit change ΔL is defined as ΔL = g(L) = f(L) − L, we have the stability condition \(-2 < {g}^{{\prime} }({L}^{* }) < 0\).
固定点仅在\(1<{f}^{{\ prime}}({l}^{*})<1 \)时才稳定。因为logit更改Δl被定义为Δl= g(l)= f(l) - l,我们具有稳定性条件\(-2 <{g}^{{{\ prime}}}({l}^{* {*})<0 \)。
Effective learning rate and slope
有效的学习率和坡度
In the one-dimensional RL models with prediction error updates and constant learning rate α, we have
在具有预测错误更新和恒定学习率α的一维RL模型中,我们有
$$g(L)=\alpha ({L}^{* }-L),$$ (53)
$$ g(l)= \ alpha({l}^{*} -l),$$(53)
where g(L) is the logit change at L. In general, to obtain a generalized form of g(L) = α(L)(L* − L) with a non-constant learning rate, we define the effective learning rate α(L) at L relative to a stable fixed point L* as:
其中g(l)通常是L.的logit变化,以获得非固定学习率的g(l)=α(l)(l)(l*-l)的广义形式,我们在l相对稳定的固定点L* AS的有效学习率α(l)定义。
$$\alpha (L)=-\frac{g(L)-g({L}^{* })}{L-{L}^{* }}=-\frac{g(L)}{L-{L}^{* }}.$$ (54)
$ \ alpha(l)= - \ frac {g(l)-g({l}^{*})}} {l- {l- {l}^{*}}} = - \ frac {g(l)} {l- {l- {l- {l}
At L*, α(L*) is the negative slope \(-{g}^{{\prime} }({L}^{* })\) of the tangent at L*. However, for general L ≠ L*, α(L) is the negative slope of the secant connecting (L, g(L)) and (L*, 0), which is different from \(-{g}^{{\prime} }(L)\).
在l*,α(l*)是负斜率\( - {g}^{{\ prime}}}}}({l}^{*})\)的l*。但是,对于一般l≠l*,α(l)是连接(l,g(l))和(l*,0)的割线的负斜率,这与\ \( - {g}^{{\ prime}}(l)\)不同。
We have
我们有
$$\begin{array}{l}{\alpha }^{{\prime} }(L)\delta L\,\approx \,\alpha (L+\delta L)-\alpha (L)\\ \,\,\,=\,\frac{g(L)}{L-{L}^{* }}-\frac{g(L+\delta L)}{L+\delta L-{L}^{* }}\\ \,\,\,\approx \,\frac{-\alpha (L)-{g}^{{\prime} }(L)}{L-{L}^{* }}\delta L.\end{array}$$ (55)
$$ \ begin {array} {l} {\ alpha}^{{{\ prime}}}}}(l)\ delta l \,\ ailt \ ailt \ ailpha(l+\ delta l) - \ alpha(\ alpha(l)(l)\,\,\,= \,\ frac {g(l)} {l- {l- {l}^{*}} - \ frac {g(l+\ delta l)} {l+\ delta l- {l- {l}(l) - {g}^{{\ prime}}}(l)} {l- {l}
Letting δL go to zero, we have:
让ΔL降至零,我们有:
$$\alpha (L)=-{g}^{{\prime} }(L)-{\alpha }^{{\prime} }(L)(L-{L}^{* }),$$ (56)
$ \ alpha(l)= - {g}^{\ prime}}}}(l) - {\ alpha}^{{\ prime}}}}}}}}(l)(l- {l}^{*{*}),$$(56)
which provides the relationship between the effective learning rate α(L) and the slope of the tangent \({g}^{{\prime} }(L)\).
这提供了有效学习率α(l)与切线\({g}^{{\ prime}}(l)\)之间的关系。
Models with d >1
D>1的模型
In models with more dynamical variables, ΔL(t) is no longer solely a function of the input and L(t) due to added degrees of freedom. In these models, the state space is spanned by a set of dynamical variables, collected by the vector F(t). For example, the action value vector is the \(F(t)={({Q}_{t}({A}_{1}),{Q}_{t}({A}_{2}))}^{T}\) in the two-dimensional RL models. The vector field ΔF(t) can be defined as \(\Delta F(t)=F(t+1)-F(t)={({Q}_{t+1}({A}_{1})-{Q}_{t}({A}_{1}),{Q}_{t+1}({A}_{2})-{Q}_{t}({A}_{2}))}^{T}\), a function of F(t) and the input in trial t.
在具有更动力学变量的模型中,由于增加的自由度,ΔL(t)不再仅仅是输入和l(t)的函数。在这些模型中,状态空间由一组动力学变量跨越,由向量F(t)收集。例如,动作值向量为\(f(t)= {({q} _ {t}({a} _ {1}),{q} _ {t}(t}(a} _ {a} _ {2} _ {2}))向量场ΔF(t)可以定义为\(\ deltaf(t)= f(t+1)-f(t)= {({Q} _ {t+1}({a} _ {1}) - {q} _ {t}({a})_ {1}),{q} _ {t+1}({a} _ {2})) - {q} _ {t}(t}(a} _} _ {2} _ {2}))}^{t}),F(t)的函数和试验中的输入。
Dynamical regression
动力回归
For one-dimensional models with states characterized by the policy logit L(t), we can approximate the one-step dynamics for a given input with a linear function—that is, ΔL ~ β 0 + β L L. The coefficients β 0 and β L can be computed via linear regression, or ‘dynamical regression’ given its use in modelling dynamical systems. Here, β 0 is similar to the preference setpoint and β L is similar to learning rates in RL models.
对于具有策略logit l(t)为特征的状态的一维模型,我们可以近似具有线性函数的给定输入的一步动力学,也就是说,Δl〜β0 +βl l l l l。可以通过线性回归或“动态回归”来计算系数的β0和βL。在这里,β0与偏好设定点相似,βL与RL模型中的学习率相似。
For models with more than one dynamical variable, we can use a similar dynamical regression approach to extract a first-order approximation of the model dynamics via linearizations of vector fields. To facilitate interpretation, we consider only d-dimensional RNNs with a d-unit diagonal readout layer (denoted by L i (t) or P i (t); a non-degenerate case).
对于具有多个动态变量的模型,我们可以使用类似的动态回归方法通过向量场的线性化提取模型动力学的一阶近似。为了促进解释,我们仅考虑具有D-UNIT对角读数层的D维RNN(由L I(T)或P I(T)表示;非脱位情况)。
For tasks with a single choice state (Supplementary Results 1.4 and 1.5), the diagonal readout layer means that d is equal to the number of actions. Thus P i (t) corresponds to the action preference for A i at trial t (before softmax). A special case of P i (t) is equal to βV t (A i ) in cognitive models. We use ΔP i (t) = P i (t + 1) − P i (t) to denote preference changes between two consecutive trials. For the reversal learning task and three-armed reversal learning task, we consider ΔP i (t) as an (approximate) linear function of P 1 (t), …, P d (t) for different (discrete) task inputs (that is, \(\Delta {P}_{i} \sim {\beta }_{0}^{({P}_{i})}+{\sum }_{j=1}^{d}{\beta }_{{P}_{j}}^{({P}_{i})}{P}_{j}\)). For the four-armed drifting bandit task, we further include the continuous reward r as an independent variable (that is, \(\Delta {P}_{i} \sim {\beta }_{0}^{({P}_{i})}+{\beta }_{R}^{({P}_{i})}r+{\sum }_{j=1}^{d}{\beta }_{{P}_{j}}^{({P}_{i})}{P}_{j}\)).
对于具有单个选择状态的任务(补充结果1.4和1.5),对角线读数层表示D等于动作数量。因此,p i(t)对应于试验t的i的动作偏好(在softmax之前)。P I(t)的特殊情况等于认知模型中的βVT(A I)。我们使用ΔPI(t)= p i(t + 1)-p i(t)表示两次连续试验之间的偏好变化。对于逆转学习任务和三臂逆转学习任务,我们将ΔPI(t)视为p 1(t),…,p d(t)的(离散)任务输入的(\ \ \(\ delta {p} _ {p} _} _ {i} \ sim {\ sim {\ sim {\ sim {} _ {0}^{({p} _ {i})}+{\ sum} _ {j = 1}^{d} {d} {\ beta} _ {{p} _ {j} _ {j}}}}^}^{p} {(p} _}}}对于四臂漂移匪徒任务,我们将连续奖励r作为自变量(即,\(\ delta {p} _ {i} \ sim {\ sim {\ beta} _ {0} _ {0}^{({p} _ {p} _ {i} _ {i}}+{\ beta)} _ {r}^{({p} _ {i})} r+{\ sum} _ {j = 1}^{d} {d} {\ beta} _ {{p} _ {p} _ {j}}}}}}^}^(p}^(p} _} _}}
For the original two-stage task, where there are three choice states (Supplementary Result 1.6), we focus on the three-dimensional model with a diagonal readout layer. Here, L 1 , L 2 and L 3 represent the logits for A 1 /A 2 at the first-stage state, logits for B 1 /B 2 at the second-stage state S 1 and logits for C 1 /C 2 at the second-stage state S 2 , respectively. We similarly consider the regression \(\Delta {L}_{i} \sim {\beta }_{0}^{({L}_{i})}+{\sum }_{j=1}^{3}{\beta }_{{L}_{j}}^{({L}_{i})}{L}_{j}\).
对于原始的两阶段任务,有三个选择状态(补充结果1.6),我们专注于具有对角线读数层的三维模型。在这里,L 1,L 2和L 3代表在第一阶段状态下A 1 /A 2的逻辑,在第二阶段s 1处的B 1 /B 2的logits和c 1 /c 2的ligits在第二阶段s 2处的logitt。我们同样考虑回归\(\ delta {l} _ {i} \ sim {\ beta} _ {0}^{({l} _ {l} _ {i} _ {i})}+{\ sum} _ {\ sum} _ {} _ {{l} _ {j}}}^{({l} _ {i})} {l} _ {j} \)。
Collecting all the \({\beta }_{{L}_{j}}^{({L}_{i})}\) (similarly for \({\beta }_{{P}_{j}}^{({P}_{i})}\)) regression coefficients for a given input condition, we have the input-dependent state-transition matrix A, akin to the Jacobian matrix of nonlinear dynamical systems:
收集所有\({\ beta} _ {{l} _ {j}}}^{({l} _ {i})} \)\)(类似地for \ for \({\ beta} _ {_ {p} {p} _ {j} _}}}}}}}}给定的输入条件,我们具有输入依赖性状态转变矩阵A,类似于非线性动态系统的雅各布矩阵:
$${\bf{A}}=\left[\begin{array}{cccc}{\beta }_{{L}_{1}}^{({L}_{1})} & {\beta }_{{L}_{2}}^{({L}_{1})} & \cdots & {\beta }_{{L}_{d}}^{({L}_{1})}\\ {\beta }_{{L}_{1}}^{({L}_{2})} & {\beta }_{{L}_{2}}^{({L}_{2})} & \cdots & {\beta }_{{L}_{d}}^{({L}_{2})}\\ \vdots & \vdots & \ddots & \vdots \\ {\beta }_{{L}_{1}}^{({L}_{d})} & {\beta }_{{L}_{2}}^{({L}_{d})} & \cdots & {\beta }_{{L}_{d}}^{({L}_{d})}\end{array}\right]$$
$$ {\ bf {a}} = \ left [\ begin {array} {cccc} {\ beta} _ {{l} {l} _ {1}}}}^{({l} _ {1} _ {1}}}} _ {{{l} _ {2}}}^{({L} _ {1})}&\ cdots&{\ beta} _ {{l} {l} _ {d}}}}}}}} _ {{{l} _ {1}}}^{({l} _ {2})}}} _ {{{l} _ {d}}^{({l} _ {2})}} \\\\\\\\\\\\\\ \ \ \ vdots&\ vdots&\ ddots&\ vdots&\ vdots \\\\\\\\\\\ {\ beta} _}{\ beta} _ {{l} _ {2}}}^{({l} _ {d})}&\ cdots&{\ beta} _ {{l} {l} _ {d} _ {d}}}}}^{l}^{(
Note that the model-free RL models in these tasks are fully characterized by the collection of all regression coefficients in our dynamical regression.
请注意,这些任务中的无模型RL模型的完全表征是我们的动态回归中所有回归系数的收集。
Symbolic regression
符号回归
Apart from the two-dimensional vector field analysis, symbolic regression is another method for discovering concise equations that summarize the dynamics learned by RNNs. To accomplish this, we used PySR70 to search for simple symbolic expressions of the updated dynamical variables as functions of the current dynamical variables for each possible input I (for the RNN with d = 2 and a diagonal readout matrix). Ultimately, this process revealed a model-free strategy featuring the drift-to-the-other rule.
除了二维矢量场分析外,符号回归是发现简洁方程的另一种方法,可以汇总RNN所学的动力学。为此,我们使用PYSR70来搜索更新的动态变量的简单符号表达式,作为每个可能输入i的当前动态变量的功能(对于d = 2和对角线读取矩阵的RNN)。最终,此过程揭示了一种无模型的策略,该策略以漂移到其他规则为特色。
Model validation via behaviour-feature identifier
通过行为-Feature标识符进行模型验证
We proposed a general and scalable approach based on a ‘behaviour-feature identifier’. In contrast to conventional model recovery, this approach provides a model-agnostic form of validation to identify and verify the hallmark of the discovered strategy in the empirical data.
我们提出了一种基于“行为特征标识符”的一般可扩展方法。与常规模型恢复相反,该方法提供了一种模型不合时宜的验证形式,以识别和验证经验数据中发现的策略的标志。
For a given task, we collect the behavioural sequences generated by models that exhibit a specific feature (positive class) and by those that do not (negative class). An RNN identifier is then trained on these sequences to discern their classes. Subsequently, this identifier is applied to the actual behavioural sequences produced by subjects.
对于给定的任务,我们收集表现出特定特征(正类别)的模型以及不(负类)的模型产生的行为序列。然后对RNN标识符进行这些序列的培训,以辨别其课程。随后,该标识符应用于受试者产生的实际行为序列。
We built identifiers to distinguish between the RNN models (positive class) and model-free RL models (negative class) in the reversal learning task, and between the RNN models (positive class) and model-based RL models (negative class) in the two-stage task. We presented the results in Supplementary Fig. 29.
我们构建了标识符,以区分逆转学习任务中的RNN模型(正类别)和无模型RL模型(负类),以及在两个阶段任务中的RNN模型(正类)(正类)和基于模型的RL模型(负类)。我们在补充图29中介绍了结果。
Meta-RL models
元RL模型
We trained meta-RL agents on the two-stage task (common transition: Pr(S 1 ∣A 1 ) = Pr(S 2 ∣A 2 ) = 0.8, rare transition: Pr(S 2 ∣A 1 ) = Pr(S 1 ∣A 2 ) = 0.2; see Supplementary Fig. 27) implemented in NeuroGym (v.0.0.1)71. Each second-stage state leads to a different probability of a unit reward, with the most valuable state switching stochastically (Pr(r = 1∣S 1 ) = 1 − Pr(r = 1∣S 2 ) = 0.8 or 0.2 with a probability of 0.025 on each trial). There are three periods (discrete time steps) on one trial: Delay 1, Go and Delay 2. During Delay 1, the agent receives the observation (choice state S0 and a fixation signal), and the reward (1 or 0) from second-stage states on the last trial. During Go, the agent receives the observation of the choice state and a go signal. During Delay 2, the agent receives the observation of state S 1 /S 2 and a fixation signal. If the agent does not select action A 1 or A 2 during Go or select action F (Fixate) during Delay periods, a small negative reward (−0.1) is given. The contributions of second-stage states, rewards, and actions on networks are thus separated in time.
我们训练了元rl代理的两阶段任务(公共过渡:pr(s 1°1)= pr(s 2°A 2)= 0.8,罕见过渡:pr(s 2°1)= pr(s 1°A 2)= 0.2;参见补充图27)每个第二阶段状态都会导致单位奖励的不同概率,最有价值的状态随机切换(pr(r = 1月1)= 1-pr(r = 1 r = 1 r = 1 r = 1 r = 0.8或0.2),每个试验的概率为0.025)。一个试验中有三个时期(离散的时间步):延迟1,延迟和延迟2。在延迟1期间,代理人接收观察结果(选择状态S0和固定信号),以及在上一阶段的第二阶段状态中的奖励(1或0)。在GO期间,代理会收到对选择状态和GO信号的观察。在延迟2期间,该代理会收到状态s 1 /s 2和固定信号的观察。如果代理在GO或选择操作F(固定)期间不选择操作A 1或2(固定),则给出较小的负奖励(-0.1)。因此,第二阶段状态,奖励和对网络的行动的贡献是及时分开的。
The agent architecture is a fully connected, gated RNN (long short-term memory58) with 48 units22. The input to the network consists of the current observation (state S 0 /S 1 /S 2 and a scalar fixation/go signal), a scalar reward signal of the previous time step, and a one-hot action vector of the previous time step. The network outputs a scalar baseline (value function for the current state) serving as the critic and a real-valued action vector (passed through a softmax layer to sample one action from A 1 /A 2 /F) serving as the actor. The agents are trained using the Advantage Actor-Critic RL algorithm72 with the policy gradient loss, value estimate loss, and entropy regularization. We trained and analysed agents for five seeds. Our agents obtained 0.64 rewards on average on each trial (0.5 rewards for chance level), close to optimal performance (0.68 rewards obtained by an oracle agent knowing the correct action).
代理体系结构是一个完全连接的,封闭式的RNN(长短期内存58),具有48个单位22。网络的输入由当前观察结果(状态S 0 /S 1 /S 2和标量固定 /GO信号),上一个时间步骤的标量奖励信号以及上一个时间步长的单式动作向量。该网络输出标量基线(当前状态的值函数),该基线是评论家和一个实用值的动作向量(通过SoftMax层通过SoftMax层以从1 /A 2 /F中采样一个动作,从1 /A 2 /F中作为Actor。使用优势参与者 - 批判性RL算法对代理进行培训,其政策梯度损失,价值估计损失和熵正则化。我们培训并分析了五种种子的剂。我们的代理商在每个试验中平均获得0.64奖励(机会水平为0.5奖励),接近最佳性能(Oracle Agent知道正确的动作,获得了0.68的奖励)。
Reporting summary
报告摘要
Further information on research design is available in the Nature Portfolio Reporting Summary linked to this article.
有关研究设计的更多信息可在与本文有关的自然投资组合报告摘要中获得。